極致課堂 | 基於深度神經網路的語音合成
語音合成(Text-To-Speech)是通過計算機將文字轉換成語音的過程。隨著語音合成技術的發展和成熟,使用者難以區分真實音和合成音。
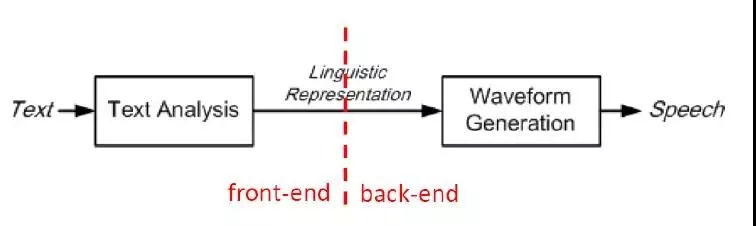
語音合成通常有以下幾種方法:
一、基於波形拼接的方法
基於波形拼接的語音合成方法,基於目標基元的上下文資訊,(如在短語中的位置、詞性等)從錄製的音庫中找到相似的基元。用同樣方式將所有基元拼在一起生成出合成語音。此方法優點是聲音清晰,缺點是基元之間可能不連貫,從而影響到合成語音的自然度。
二、基於HMM統計引數的語音合成

基於HMM統計引數的語音合成簡單來說採用HMM對各個發音單元進行高斯建模,利用高斯模型的均值和方差生成語音引數,通過聲碼器輸出合成後的語音。這種方法的優點是合成聲音圓潤,缺點是受限於聲碼器、HMM建模精度不足等因素,使得合成的語音表現力弱,合成聲音發悶。
三、基於深度神經網路的語音合成
隨著深度學習技術的不斷成熟,基於深度神經網路的語音合成逐漸成為語音合成領域的主流方法;利用深層神經網路強大的非線性建模能力,有效提升建模精度。
深度信念網路(DBN):用DBN替換GMM,用DBN構建文字引數到語音引數之間的對映。
深度混合密度網路(DMDN):如圖,前面是DNN,但輸出層的引數經過簡單計算可以對應到高斯函式的引數(均值、方差)上,尤其是多高斯混合時每個高斯的權重都都可以通過輸出層引數簡單地公式對映得到,可以認為網路輸出就是高斯混合函式的引數。

該方法的好處是,輸入文字經過分析和預處理後送到DMDN模型中,輸出不是語音生成引數而是高斯混合函式引數,在此基礎上利用傳統HMM思路生成語音,效能明顯提高。
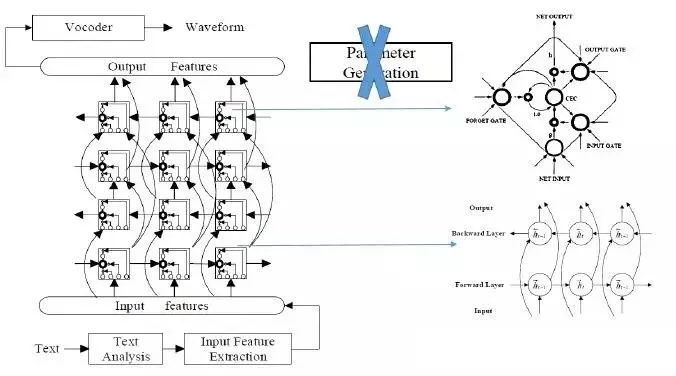
語音合成是連續動態過程,需要考慮語義、句法、詞性等資訊,這些資訊與其所在的上下文資訊關聯性很強,所以語音合成時需要考慮文字的一系列上下文的內容以及聲學層中歷史資訊的影響,所以DBLSTM-RNN相對效果更好。
深度雙向長短時記憶網路(DBLSTM-RNN):優勢在於跳過了引數生成演算法,直接預測每幀語音引數。語音合成需要對文字做很多處理,如分析短語邊界、詞性、拼音等,通常使用貝葉斯決策、條件隨機場、最大熵等方法,這些都可以用深度神經網路代替。聲學層再做一個深度神經網路,將兩個網路聯合建模,不需要HMM,輸入文字,經神經網路輸出語音引數,再經聲碼器就可得到很好的聲音。
谷歌WaveNet:主要思想如下,語音的波形就是各個取樣點,每個取樣點都受先前若干取樣點的影響,存在條件概率密度函式,波形的聯合概率可用條件概率分佈的乘積來建模。
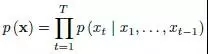
WaveNet將條件概率分佈用多層卷積層建模,輸出層不是普通意義上取樣的語音波形,而是採用μ-律壓縮後的結果。訓練的細節包括用殘差反饋進行區分性訓練,以及採用skip connections,跳躍某些時序特徵的約束,增多訓練層數,最後採用Conditional WaveNet啟用函式將資訊綜合起來訓練。WaveNet的結果超過之前所有系統。詳細內容參考文獻:Oord A V D, Dieleman S, Zen H, et al. WaveNet: A Generative Model for Raw Audio[J]. 2016.

如何利用語音合成技術生成出多風格、富有情感的語音還需要持續努力探索新的方法。極限元在情感語音合成領域與國際接軌,其創始團隊源自中科院自動化研究所併成立“智慧互動聯合實驗室”,號稱語音合成界的“黃埔軍校”;在人工智慧領域有20多年技術積累,在國際會議和期刊上發表論文400餘篇,申請語音及音訊領域專利100餘項;作為負責人、科研骨幹參與多項國家自然基金專案、國家863專案和國家重點研發計劃等專案,獲得多媒體情感競賽第二名、北京市自然科學進步二等獎、中國專利獎優秀獎、北京科技進步獎、Eurospeech大會獎等多種獎項。