PSO演算法的改進(引數)
# # 基本PSO的改進
雖然粒子群在求解優化函式時,表現了較好的尋優能力;通過迭代尋優計算,能夠迅速找到近似解;
但基本的PSO容易陷入區域性最優,導致結果誤差較大。
兩個方面:
1.將各種先進理論引入到PSO演算法,研究各種改進和PSO演算法;(混沌技術,神經網路技術,自適應技術)
2.將PSO演算法和其它智慧優化演算法相結合,研究各種混合優化演算法,
達到取長補短、改善演算法某方面效能的效果。
近時期粒子群改進策略主要體現的方面:
1.PSO演算法的慣性權重模型,通過慣性權重的引入,提高了演算法的全域性搜尋能力;
2.帶鄰域操作的PSO模型,克服PSO模型在優化搜尋後期隨迭代次數增加搜尋結果無明顯改進的缺點;
3.協同PSO演算法,用K個相互獨立的粒子群分別在D維的目標搜尋空問中的不同維度方向上進行搜尋;



*藍色的曲線:w=0.8,黃色的曲線:w=0.6紅色的曲線:w=0.4*
從上式可以看出,w越大,微粒飛行速度越大,微粒將以較大的步長進行全域性搜尋;w越小,則微粒步長小,趨向於精細的區域性搜尋。
同時,從右圖也可以看出w=0.8時,微粒以更少的迭代次數取得全域性最優;w=0.6時,迭代次數其次,
w=0.4時,迭代次數相對較多。
雖然較大的權重因子有利於跳出區域性最小值,便於全域性搜尋, 而較小的慣性因子則有利於對當前的搜尋區域進行精確區域性搜尋, 以利於演算法收斂;但是w過大容易導致“早熟收斂”與演算法後期 在全域性最優解附近產生振盪的現象。
**w的改進**
一般方法是把Wmax逐漸變成Wmin;
**1.權重線性遞減的PSO演算法**





自適應權重粒子群優化演算法適應度曲線
2.自適應權重的PSO演算法

f表示微粒當前的目標函式值。
當各微粒的目標值趨於一致或趨於區域性最優時,將使慣性權重增大,而各微粒的目標值比較分散時,使慣性權重減小,同時對於目標函式值優於平均目標值的微粒,其對應的慣性權重因子較小,從而保留了該微粒,反之對於目標函式值差於平均目標值的微粒,其對應的慣性權重因子較大,使得該微粒向較好的搜尋區域靠攏。(附圖)

慣性權重線性遞減PSO演算法適應度曲線
3.隨機權重策略的PSO演算法

隨機地選取值,使得微粒歷史速度對當前速度的影響是隨機的。
為服從某種隨機分佈的隨機數,從一定程度上可從兩方面克服 w的線性遞減所帶來的不足。
隨機權重策略的PSO演算法對於多峰函式,能在一定程度上避免陷入區域性最優。

[隨機權重策略的PSO適應度曲線]
4.增加收縮因子的PSO演算法





壓縮因子 比慣性權重係數w更能有效地控制與約束微粒的飛行速度,同時也增強了演算法的區域性搜尋能力。

帶壓縮因子的的PSO演算法適應度曲線

由上面兩個圖,可以看出慣性常數方法通常採用慣性權值隨更新代數增加而遞減的策略,在演算法後期由於慣性權值過小,會失去微粒的探索新區域的能力,而壓縮因子方法則不存在此不足。
**CONCLUTIONS**
PSO演算法的搜尋效能取決於其全域性搜尋與區域性改良能力的平衡,這很大程度上依賴於演算法的引數控制,包括N,Vmax,M,w,c1,c2等;
**微粒種群數目N**:N設定較小時,演算法收斂速度快,但是容易陷入區域性最優;N設定較大時,演算法收斂速度相對較慢;導致計算時間大幅增加,而且群體數目N增至一定的水平時,再增加微粒數目不再有顯著的效果。
參考取值:一般設N為10~50之間,對於比較複雜的問題,微粒數目N可以取100以上;
**最大速度Vmax**:決定搜尋的力度;Vmax過大,粒子運動速度快,微粒探索能力強,但容易越過最優的搜尋空間,錯過最優解;如果Vmax較小,微粒的開發能力強,容易進入區域性最優,可能會使微粒無法運動足夠遠的距離以跳出區域性最優,從而也可能找不到解空間的最佳位置。(跟w的取值規則一樣)。
**慣性權值w**:w越大,微粒飛行速度越大,微粒將會以更長的步長進行全域性搜尋;w較小,則微粒步長小,趨向於精細的區域性搜尋;因此,我們採用動態改變w的值;在搜尋初期設w取一個較大值,然後隨著迭代次數的不斷增加,逐漸降低w的值;從而達到全域性最優。
**ways**:隨機調整,線性遞減,非線性遞減,模糊自適應。
**學習因子c1,c2**:c1,c2具有自我總結和向優秀個體學習的能力,從而使微粒向群體內或領域內的最優點靠近。c1,c2分別調節微粒向個體最優或者群體最優方向飛行的最大步長,決定微粒個體經驗和群體經驗對微粒自身執行軌跡的影響。學習因子較小時,可能使微粒在遠離目標區域內徘徊;學習因子較大時,可使微粒迅速向目標區域移動,甚至超過目標區域。因此,c1和c2的搭配不同,將會影響到PSO演算法的效能。
**ways**:一般令c1+c2=4;其實c1=2附近的迭代次數較小,在兩個端點0和4附近的迭代次數較大,大致呈現出對稱性;在倆端點處搜尋失敗率較大;通常,越接近端點,失敗率越高。但並不是所有情況都是c1=c2=2時才有最優解。
r1,r2是[0,1]之間的隨機數。
**最大迭代次數M**:演算法停止迭代條件。
另外,隨著變數範圍和維數的增加,搜尋空間呈幾何級擴張,迭代次數相應增加,優化函式越複雜,所需的計算量越大,迭代次數也越多。
引數的選擇影響演算法的效能和效率,也是一個值得優化的問題。在實際應用中,沒有選擇引數的通用方法,只能憑經驗選取。大量的模擬實驗發現,引數對演算法效能的影響有一定的規律可尋。例如:w=0.7298,c1=c2=1.49618是一組較為出色的引數組合。
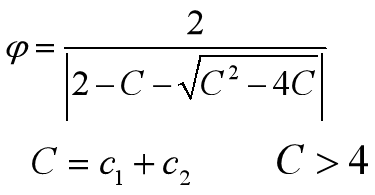
謝謝大家~~~~~~
歡迎大家和我一起討論,一起進步。
有需求可聯絡本人郵箱[email protected]