[譯][譯]C++17,標準庫新引入的並行演算法
看到一個介紹 C++17 的系列博文(ofollow,noindex" target="_blank">原文 ),有十來篇的樣子,覺得挺好,看看有時間能不能都簡單翻譯一下,這是第七篇~
C++17 對 STL 演算法的改動,概念上其實很簡單.標準庫之前有超過100個演算法,內容包括搜尋,計數,區間及元素操作等等.新標準過載了其中69個演算法並新增了7個演算法.過載的演算法和新增的演算法都支援指定一個所謂執行策略(execution policy)的引數,通過調整這個引數,你可以指定演算法是以序列,並行或者向量並行的方式來執行.
我之前的文章 介紹了很多過載的標準庫演算法,有興趣的朋友可以看看.
這次,我要介紹一下 C++17 新引入的7個演算法:
std::for_each_n std::exclusive_scan std::inclusive_scan std::transform_exclusive_scan std::transform_inclusive_scan std::parallel::reduce std::parallel::transform_reduce
其中除了 std::for_each_n 之外,其他幾個演算法的名字都很特殊.為了理解方便,我先介紹一下Haskell 中相關的內容,之後再回到C++的講解中.
A short detour
C++17 新引入的演算法在純函式式語言 Haskell 中都有對應的方法.
- for_each_n 對應的方法為 map.
- exclusive_scan 和 inclusive_scan 對應的方法為 scanl 和 scanl1
- transform_exclusive_scan 等同於組合使用 map 和 scanl, 而 transform_inclusive_scan 等同於組合或者 map 和 scanl1.
- reduce 對應 foldl 或者 foldl1.
- transform_reduce 對應 map 和 foldl 的組合或者 map 和 foldl1 的組合.
開始講解之前,讓我簡單說一下這些方法的功能作用.
- map 可以對一個列表應用一個函式
- foldl 和 foldl1 可以對一個列表應用一個二元運算並將結果歸納為一個數值.foldl 與 foldl1 相比額外需要一個初始值.
- scanl 和 scanl1 的操作與 foldl 和 foldl1 基本一致,但是他們會產生所有的中間結果,所以最終你會獲得一個列表,而不是一個數值.
- foldl, foldl1, scanl 和 scanl1 的操作都是從列表的左側開始.
下面是一個 Haskell 的相關示例
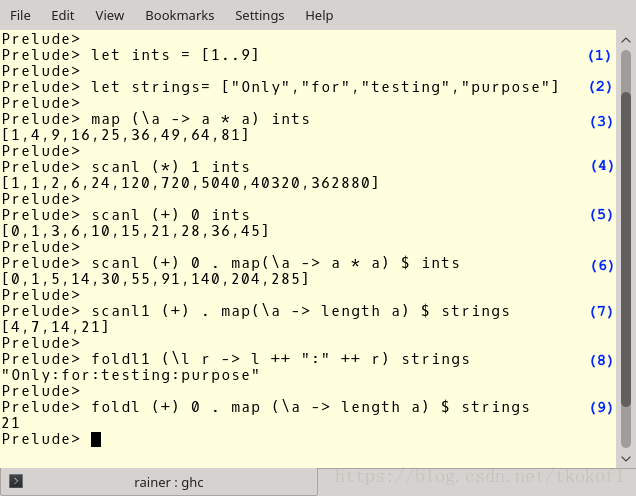
(1) 和 (2) 處的程式碼分別定義了一個整數列表(ints)和一個字串列表(strings).在 (3) 中,我給整數列表(ints)應用了一個 lambda 函式(\a -> a * a).(4) 和 (5) 則更加複雜些:(4) 中我將整數列表中的所有整數對相乘(乘法單位元素1作為初始元素).(5) 中則做了所有整數對相加的操作.(6), (7), 和 (9) 中的操作可能有些難以理解,你必須從右往左來閱讀這幾個表示式.scanl1 (+) . map(\a -> length a) (即(7)) 是一個函式組合,其中的點號(.)用以組合左右兩個函式.第一個函式將列表中的元素對映為元素的長度,第二個函式則將這些對映的長度相加.(9) 中的操作和 (7) 很相似,不同之處在於 foldl 只產生一個數值(而不是列表)並且需要一個初始元素(我指定初始元素為0),現在,表示式(8)看起來應該比較簡單了,他以”:”作為分隔符連線了列表中的各個字串元素.
我想你也許好奇為什麼我要在介紹C++的文章中寫這麼多 Haskell 的內容(這些內容還頗具挑戰性),那是因為兩個原因:
1. 你可以知道 C++ 中相應演算法的歷史
2. 比照 Haskell 的對應方法可以幫助我們理解 C++ 中 的相應演算法.
好了,我們終於看個C++的示例了.
The seven new algorithms
做好心理準備,下面的程式碼可能有些難讀.
#include <iostream>
#include <string>
#include <vector>
#include <execution>
int main()
{
std::cout << std::endl;
// for_each_n
std::vector<int> intVec{ 1, 2, 3, 4, 5, 6, 7, 8, 9, 10 };// 1
std::for_each_n(std::execution::par,// 2
intVec.begin(), 5, [](int& arg) { arg *= arg; });
std::cout << "for_each_n: ";
for (auto v : intVec) std::cout << v << " ";
std::cout << "\n\n";
// exclusive_scan and inclusive_scan
std::vector<int> resVec{ 1, 2, 3, 4, 5, 6, 7, 8, 9 };
std::exclusive_scan(std::execution::par,// 3
resVec.begin(), resVec.end(), resVec.begin(), 1,
[](int fir, int sec) { return fir * sec; });
std::cout << "exclusive_scan: ";
for (auto v : resVec) std::cout << v << " ";
std::cout << std::endl;
std::vector<int> resVec2{ 1, 2, 3, 4, 5, 6, 7, 8, 9 };
std::inclusive_scan(std::execution::par,// 5
resVec2.begin(), resVec2.end(), resVec2.begin(),
[](int fir, int sec) { return fir * sec; }, 1);
std::cout << "inclusive_scan: ";
for (auto v : resVec2) std::cout << v << " ";
std::cout << "\n\n";
// transform_exclusive_scan and transform_inclusive_scan
std::vector<int> resVec3{ 1, 2, 3, 4, 5, 6, 7, 8, 9 };
std::vector<int> resVec4(resVec3.size());
std::transform_exclusive_scan(std::execution::par,// 6
resVec3.begin(), resVec3.end(),
resVec4.begin(), 0,
[](int fir, int sec) { return fir + sec; },
[](int arg) { return arg *= arg; });
std::cout << "transform_exclusive_scan: ";
for (auto v : resVec4) std::cout << v << " ";
std::cout << std::endl;
std::vector<std::string> strVec{ "Only", "for", "testing", "purpose" };// 7
std::vector<int> resVec5(strVec.size());
std::transform_inclusive_scan(std::execution::par,// 8
strVec.begin(), strVec.end(),
resVec5.begin(),
[](auto fir, auto sec) { return fir + sec; },
[](auto s) { return s.length(); });
std::cout << "transform_inclusive_scan: ";
for (auto v : resVec5) std::cout << v << " ";
std::cout << "\n\n";
// reduce and transform_reduce
std::vector<std::string> strVec2{ "Only", "for", "testing", "purpose" };
std::string res = std::reduce(std::execution::par,// 9
strVec2.begin() + 1, strVec2.end(), strVec2[0],
[](auto fir, auto sec) { return fir + ":" + sec; });
std::cout << "reduce: " << res << std::endl;
// 11
std::size_t res7 = std::transform_reduce(std::execution::par,
strVec2.begin(), strVec2.end(), 0u,
[](std::size_t a, std::size_t b) { return a + b; },
[](std::string s) { return s.length(); }
);
std::cout << "transform_reduce: " << res7 << std::endl;
std::cout << std::endl;
return 0;
}
與 Haskell 中的示例對應,我使用 std::vector 建立了整數列表 (1) 和字串列表 (7).
在程式碼 (2) 處,我使用 for_each_n 將(整數)列表的前5個整數對映成了整數自身的平方.
exclusive_scan (3) 和 inclusive_scan (5) 非常相似,都是對操作的元素應用一個二元運算,區別在於 exclusive_scan 的迭代操作並不包含列表的最後一個元素, Haskell 中對應的表示式為: scanl (*) 1 ints.(譯註:結果並不完全等同, Haskell 的 scanl 操作包含列表最後一個元素,後面提到的相關 Haskell 對應也是如此,注意區別)
transform_exclusive_scan (6) 執行的操作有些複雜,他首先將 lambda 函式 function [](int arg){ return arg *= arg; } 應用到列表 resVec3 的每一個元素上,接著再對中間結果(由上一步 lambda 函式產生的臨時列表)應用二元運算 [](int fir, int sec){ return fir + sec; }(以 0 作為初始元素),最終結果儲存於 resVec4.begin() 開始的記憶體處.Haskell 中對應表示式為:
scanl (+) 0 . map(\a -> a * a) $ ints.
(8) 中的 transform_inclusive_scan 和 transform_exclusive_scan 所執行的操作很類似,其中第一步的 lambda 函式將元素對映為了元素的長度,對應的 Haskell 表示式為:
scanl1 (+) . map(\a -> length a) $ strings.
Now, the reduce function should be quite simple to read. It puts “:” characters between each element of the input vector. The resulting string should not start with a “:” character. Therefore, the range starts at the second element (strVec2.begin() + 1) and the initial element is the first element of the vector: strVec2[0]. Here is Haskell: foldl1 (\l r -> l ++ “:” ++ r) strings.
現在,程式碼中的 reduce 函式 (9) 看起來就比較簡單了,他需要在各個(字串)元素之間放置 “:” 字元.因為結果的開頭不能帶有 “:” 字元, reduce 的迭代是從第二個元素開始的(strVec2.begin() + 1) ,並以第一個元素作為初始元素(strVec2[0]). Haskell 中對應表示式為: foldl1 (\l r -> l ++ “:” ++ r) strings.
如果你想深入瞭解一下 (11) 中的 transform_reduce,可以看看我之前的文章 ,這裡同樣給出 Haskell 中對應的表示式: foldl (+) 0 . map (\a -> length a) $ strings.
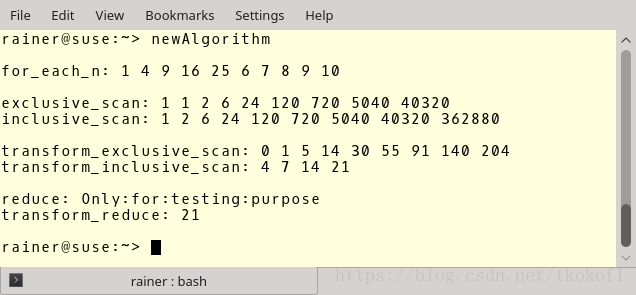
程式的輸出如下,有興趣的朋友可以仔細看看.
Final remarks
C++17 新引入的這7個演算法有很多過載版本,呼叫的時候,你可以指定初始元素,也可以不指定初始元素,同樣的,你可以指定執行策略,也可以不指定執行策略.你甚至可以在不指定二元運算的情況下呼叫需要二元運算的演算法(例如std::reduce),這種情況下,這些演算法會預設使用二元加法運算.為了能夠以並行或者向量並行的方式執行這些演算法,指定給演算法的二元運算必須滿足可結合性,這個限制也很容易理解,因為並行化的演算法很容易會在多個CPU核上同時執行(這種情況下,二元運算不可結合的話就會導致錯誤結果).更深入的一些資訊你可以看看這裡 和這裡 .