和資料濫用說再見,用少樣本學習拯救被群嘲的推薦系統
推薦系統想必大家都不陌生,一個推薦系統有多“聰明”,將在很大程度上決定了使用者是留下還是跳出,甚至可能影響一款產品的生命週期和商業價值。
在推薦系統誕生的三十多年間,不同平臺衍生出了各有特色的機制和演算法,冷啟動卻是伴隨其始終的話題。
所謂冷啟動,就是在推薦系統初期,沒有任何使用者與平臺資訊的交集資訊和行為軌跡的情況下,無法通過使用者偏好等方式進行推薦。這時,推薦系統就處於冷啟動狀態。
簡單來說,就是一個新顧客來到饅頭鋪,第一次買饅頭、也沒有任何動作表情可供揣測,如何讓他第一眼就看到自己想吃的饅頭。
今天我們就用一篇文章,看看AI在推薦系統的冷啟動上,有哪些新突破。

流量紅利耗盡後,網際網路公司還能向誰要增長?
後面我們會深入探討一些關於推薦演算法及冷啟動的技術概念,但首先,我們需要闡述一下,冷啟動到底有何價值?
先說結論:冷啟動可以讓推薦系統用最快的效率黏住新使用者。

2017年以來,所有中國網際網路公司都在流量紅利枯竭的深淵中掙扎。智慧裝置的使用者數量不再自發性增長,使用者使用時長也來到了瓶頸期,此時想要繼續擴大規模的網際網路公司,路徑無非兩個:
一是去海外市場攫取新使用者,二是在存量市場中撬走新使用者。
無論哪一種,都面臨一個難題:如何第一時間吸引住越來越缺乏耐心的使用者?
例如,某新聞資訊APP好不容易吸引了一個新使用者下載,如果他在首頁上翻了二十分鐘也看不到自己想看的內容,或許就不會再浪費時間;
同樣,如果一個大眾社交平臺在不知道使用者特徵的時候,推薦的賬號都與他心目中的理想型八竿子打不著,自然也難逃涼涼的命運。
在這些例子中,推薦系統與新使用者之間難免出現資訊與預期的不相容,往往需要使用者進行一些顯著的操作才能提高匹配的精準度,而冷啟動恰恰是推動使用者與平臺產生互動的關鍵所在。
精準的幻象:目前的冷啟動存在哪些問題?
冷啟動要與潛在使用者有效契合,問卷調查和興趣選擇,是最常見的一種。
諸如豆瓣、微博、喜馬拉雅等內容分發平臺,在使用者第一次開啟APP,都會強制註冊並採取一定的獎勵機制,引導使用者留下個人資料和感興趣的話題,主動推薦關注相關熱門賬號,以儘可能保證使用者在正式體驗過程中,能刷到自己喜歡的話題。
這種主動引導使用者留下行為軌跡的方式,可以快速積累起第一批使用者資料,做一些顆粒度比較大的推薦。

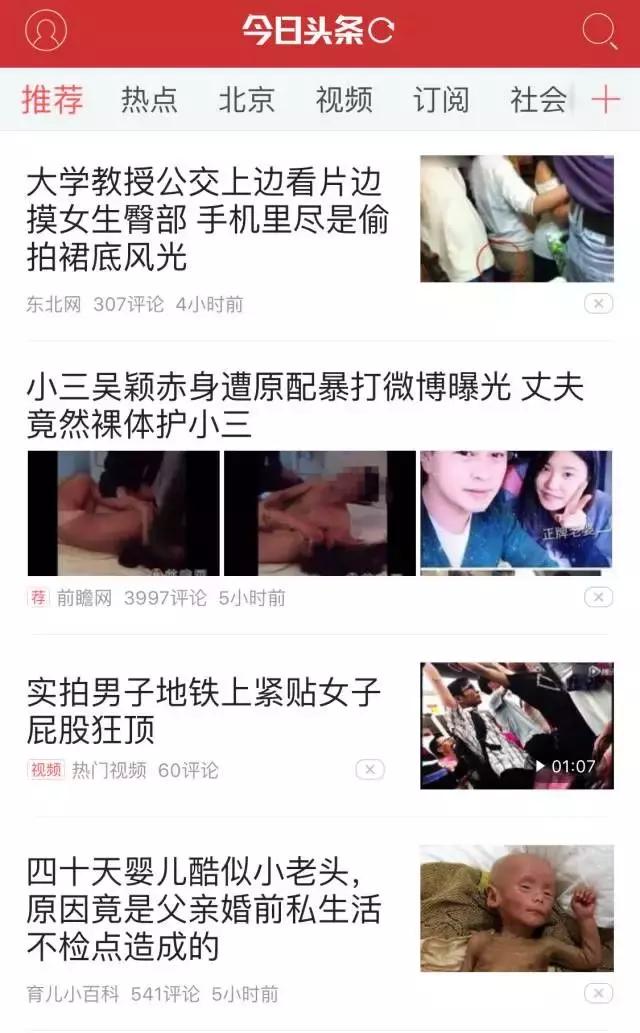
如果使用者很懶,或者不願意讓系統知道自己的個人資訊,推薦系統還可以使用熱度模型,基於統計分析推薦一些大部分人都會感興趣的熱點資訊。雖然很容易讓平臺調性顯得有點low,但從概率學角度看,說不定就正好撞到使用者心口上了呢。
比如一直強調演算法推薦的今日頭條,在冷啟動狀態就採用了這種做法,向新使用者推薦的大多是“新娘給伴娘下藥”、“孿生姐妹共侍一夫”這樣low得不要不要的內容,還是有一定效果的。
如果以上還不夠,那麼也可以採取更加激進一點的方式。比如基於大資料的協同過濾,可以根據關聯行為或關聯使用者的相似性來進行推薦。
像是採集使用者的地理位置資訊,旅遊商務、本地O2O等應用可以更有針對性地進行推薦;或者調取手機中關聯APP的使用者行為資料進行預分析。
今日頭條就曾引導使用者使用微博登入,然後爬取使用者在微博上的一些社交資料,比如動態、圖片、文章、贊過的人等等。依據這些資訊,可以判斷出使用者最近喜歡哪個明星,併為其推送相關資訊。
反正大資料時代,“凡有接觸,必留痕跡”,總有一些隱藏的資訊能夠捕捉到使用者內心的吉光片羽。
說了這麼多,我們來歸納一下傳統意義上冷啟動的內在邏輯——儘可能多地掌握使用者資訊的獲取維度。
這個過程同時也向我們揭示了一種推薦系統的集體困境,那就是,如果企業無限度地擴充套件獲取使用者資訊的渠道,必然會遭遇隱私和法律之牆;而挖掘已有的使用者資訊,資料量往往又捉襟見肘。
那麼,情況有可能發生變化嗎?少樣本學習(fewshot learning)正在嘗試解決這一問題。

少樣本學習:改變的不只一點點
不難發現,推薦系統冷啟動的眾多通用方法,都需要越多越好的標註資料才能有效發揮其作用。
但現實是,冷使用者往往不會提供那麼多的標註資料。在小資料的環境下,推薦演算法還能發揮作用嗎?
這裡就涉及到一個重要的“多臂老虎機問題(Multi-armed bandit problem, MAB)”。
當你走進一家賭場,面對20個一模一樣的老虎機,在不知道它們吐錢概率的情況下,如果可以無限制地搖下去,自然可以知道哪臺老虎機成功率最高。
但當你手裡的錢有限的時候,搖弊的次數也被限制了,該如何最大化自己的收益呢?
顯然,此時每一次搖臂的機會對你來說都是極其寶貴的。

在冷啟動中,使用者的每一次有效行為也是如此。
系統既要儘可能地擴大資訊的多樣性和寬度,又要防止過多“無用”資訊夾雜其中,讓使用者“資訊過載”。
過去,不少平臺試圖通過熱度模型來解決這個冷啟動中的“多臂老虎機問題”,給新使用者推薦目前點選率最高的結果。但這又會大大降低資訊的覆蓋率和多樣性,出現反覆推薦。

那麼,少樣本學習(fewshot learning)又是怎麼做的呢?
簡單來說,就是讓推薦引擎具備經過少量樣本訓練之後快速泛化的能力,從而在冷使用者有限的行為軌跡下,實現推薦效果的最大化。
舉個例子,電商平臺可以先用隨機試探的方式,選擇帶有不同標籤的熱門商品展示給冷使用者,並對冷使用者的有效動作進行強化學習。
比如給使用者的動作設定一個獎勵函式。使用者點選一次,收益就是1;沒有點選,收益就是0。以此測試冷使用者對哪些商品有反饋,再在此基礎上根據實際收益去調整被展示的商品。
這樣做的好處是,即便是在有限的條件下,也能快速判斷出使用者的興趣所在,降低瀏覽過程中使用者的耐心損耗,同時避免熱度模型製造的“資訊繭房”。
一個商品的收益均值越大,被選中展示給使用者的機會就越大。而那些被選次數較少的商品,也回被呈現在冷使用者面前,相當於一張“復活卡”。

又比如孿生網路,訓練時利用雙路神經網路進行交叉計算,從而得出共性特徵。再用這一模型去測試樣本,對於樣本的共性指數進行排列。這樣電商就可以通過這種共性指數來進行商品推薦,把使用者行為和商品標籤看做一對孿生資料,假如使用者與“少女”、“溫馨”這樣的資料標籤共性指數越高,那麼自然與“直男”、“酷炫”這樣的標籤共性指數越低,反之亦然。當用戶無視了粉紅色手機殼時,系統可以嘗試推薦白酒這類商品,通過實時反饋不斷縮小使用者畫像的範圍,在少量資料的前提下達到和協同推進演算法近似的效果。
除了電商,少樣本學習還能夠被應用在眾多其他領域。
比如視訊網站。
“一千個觀眾有一千個哈姆雷特”,使用者認知標準不一,讓視訊的資料標註也充滿了不確定性,無法建立龐大的標籤體系,使得視訊平臺個性化推薦的冷啟動更加困難。
從這個角度看,少樣本學習在視訊領域更有用武之地。
比如使用者的觀看長度、觀看時間段、觀看次數、跳進跳出等等行為都存在者很大的主觀性,很難用標籤語言來概括。在這種情況下,在用少量視訊“試探”冷使用者的時候,反而可以對這些主觀因素進行價值判斷並賦值,再讓機器進行線上學習,選出成功率最高的進行推薦。
並不討好的少樣本學習,會完成推薦系統的終極理想嗎?
說了這麼多不難發現,“少樣本學習”的條件要比大資料學習苛刻的多。
它將訓練範疇鎖定在了新使用者與單一平臺的有限互動之間,既不能調取外部使用者行為進行協同過濾,也不讓使用者主動告知系統自己的個人偏好,可說是完全暴露在使用者行為的資料孤島上。
在中國如此寬鬆的隱私環境下,這種探索有必要的嗎?
我認為是有的。
首先我們要知道,當前寬鬆的隱私環境一定只是一時的。相關法律法規的制定、使用者的防範意識只會越來越完善。未來資料氾濫供人取用的情況只會越來越少,如何最大程度下發揮有限資料的作用,一定是推薦系統取勝的關鍵。
同時,能用更少的資料去捕捉更多使用者,也是中國科技企業發展從流量轉向演算法的關鍵。在巨頭割據下,或許流量、再從流量中轉化資料正在成為一件奢侈的事情,但沒有資料,也就沒有精準的推薦演算法,無法留住使用者更無法商業化。而少樣本學習的出現,正在打破這個怪圈,未來崛起新企業不一定是BAT的附庸,但一定會應用少資料學習演算法。
更重要的是,冷啟動所面對的,不是等待被收割商業價值的賬號,而是一個個充滿好奇的靈魂。真正優質的推薦系統,要做的就是不斷帶來驚喜,這才是技術的終極理想。

用萊蒙托夫的一句詩結束這篇文章吧……