【週末AI課堂】CNN在Keras中的實踐 | 機器學習你會遇到的“坑”
AI課堂開講,就差你了!
很多人說,看了再多的文章,可是沒有人手把手地教授,還是很難真正地入門AI。為了將AI知識體系以最簡單的方式呈現給你,從這個星期開始,芯君邀請AI專業人士開設“週末學習課堂”——每週就AI學習中的一個重點問題進行深度分析,課程會分為理論篇和程式碼篇,理論與實操,一個都不能少!
來,退出讓你廢寢忘食的遊戲頁面,取消只有胡吃海塞的週末聚會吧。未來你與同齡人的差異,也許就從每週末的這堂AI課開啟了!
讀芯術讀者交流群,請加小編微訊號:zhizhizhuji。等你。後臺回覆“週末AI課堂”,查閱相關原始碼。
全文共1646字,預計學習時長3分鐘

本文作為上一節《卷積之上的新操作》的補充篇,將會關注一些讀者關心的問題,和一些已經提到但並未解決的問題:
- 到底該如何理解padding中的valid,same,full?
- 空洞卷積會產生什麼樣的作用?
- 如何實現inception中的多個尺寸卷積核作用在同一層上?
卷積形式的動態展示
希望以下動圖可以幫助你直觀理解卷積中的strides和padding.(圖片來源為:https://github.com/vdumoulin/conv_arithmetic)
卷積核的最簡單情形
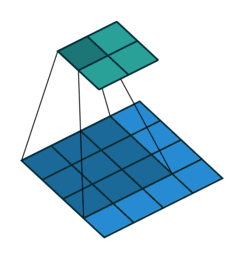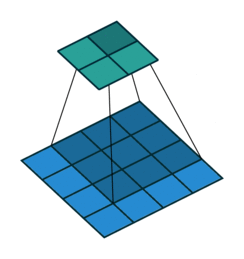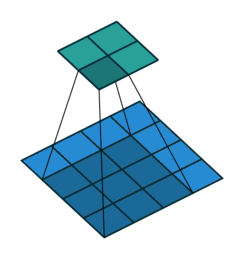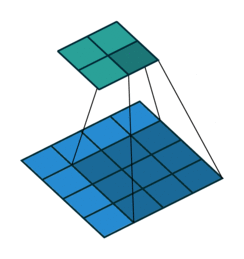
如圖,一個4*4的特徵圖被轉化為2*2的特徵圖,卷積核的大小為3,stride=1,沒有使用padding。
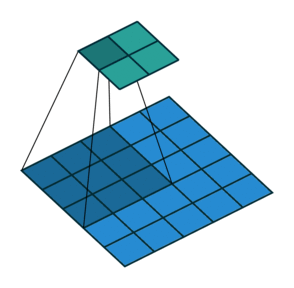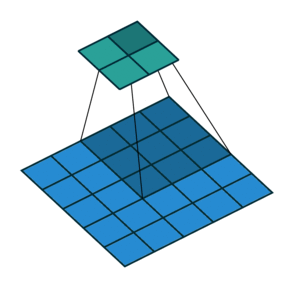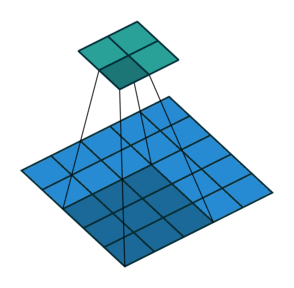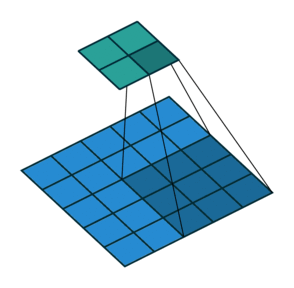
如圖,一個5*5的特徵圖被轉化為2*2的特徵圖,卷積核的大小為3,stride=2,沒有使用padding。
這些無論如何都不使用padding的情形,卷積核只會訪問到那些完全包著核的位置,一般輸出比輸入的尺寸要小,我們把它叫做有效卷積,也就是valid。
使用padding的卷積情形
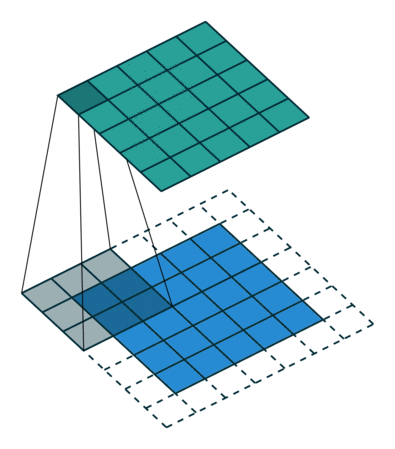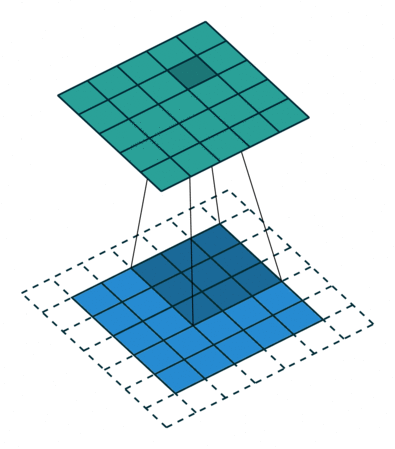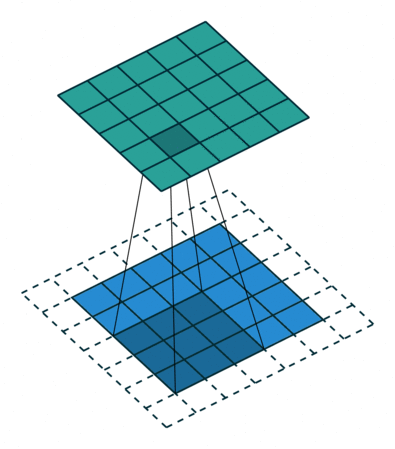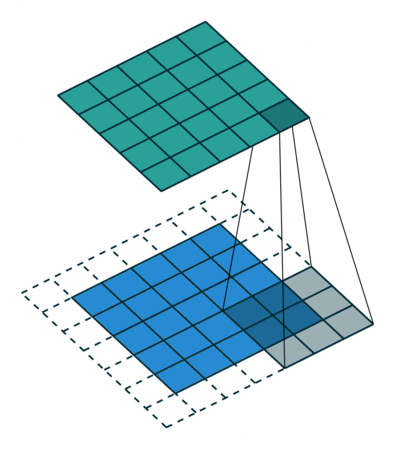
一個5*5的特徵圖被轉化為5*5的特徵圖,卷積核的大小為3,stride=1,使用padding,在這種輸入輸出保持相同尺寸的情形,我們叫相同卷積,也就是same,與stride是否為1無關。

一個5*5的特徵圖被轉化為7*7的特徵圖,卷積核的大小為3,stride=1,使用更多的padding,這種輸入特徵圖的每個元素都會被訪問3(卷積核的大小)遍,我們叫全卷積,也就是full,與stride是否為1無關。一般的,full中的輸出尺寸要大於輸入尺寸。
空洞卷積(Dilated Convolution)
空洞卷積,在不增加引數的前提下,將原有的卷積核擴大。原本的卷積操作是3*3的卷積核作用在3*3的區域內,空洞卷積則會作用在5*5的區域內,一定程度上擴大了特徵選取的範圍,也就是通常人們所說的感受野。
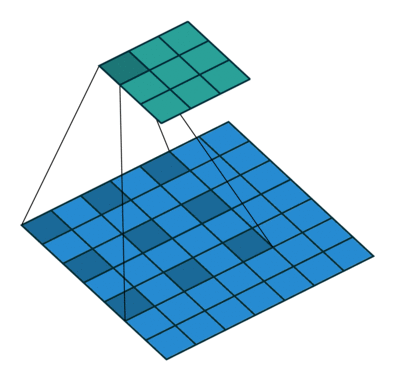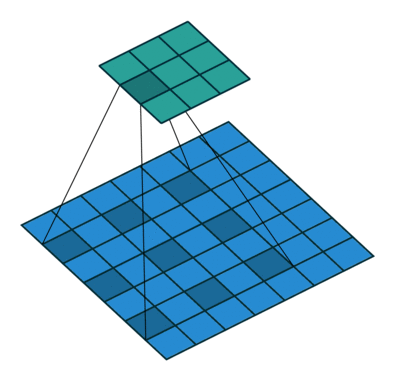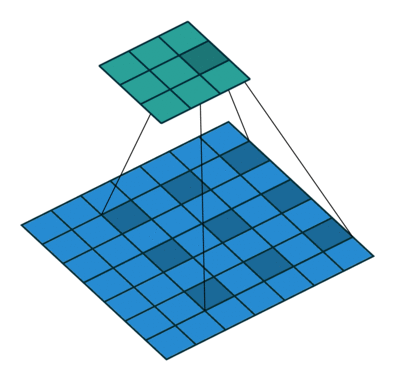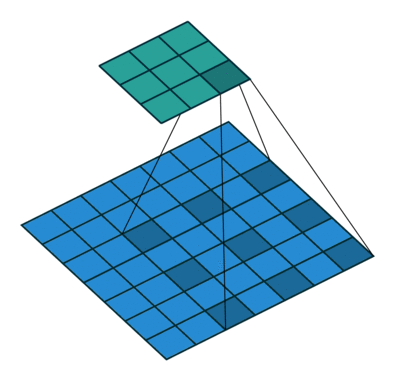
如圖,進行卷積操作的畫素點用深藍色標記,以前,3*3卷積核緊密作用於原影象,但空洞卷積作用下,卷積核的作用範圍擴大,引數數量不變,意味著有些被包括的點實際上並未參與運算,這些就是“空洞”。
在keras中實現這一點並不難,我們搭建卷積層的時候就有dilation_rate引數,我們通過它來控制空洞卷積的空洞大小,也就是控制了感受野的大小。
同一層中使用多個尺寸的卷積核
我們已經在前面對MNIST手寫識別資料中的10000個樣本分別使用了普通的全連線網路,添加捲積的網路,以及卷積+池化的網路,證明了,在引數數量遠遠小於全連線網路的情況下,CNN取得了更優的結果。
但是再進一步的提升準確率,更好的看出效果,我們最好選用更復雜的資料,MNIST手寫識別資料非常經典,是必測的資料集。但它的上限比較好到達,全連線網路就能達到93%的準確率。
所以我們將MNIST替換為fashion-MNIST資料,fashion-MNIST格式,大小與MNIST一模一樣,包含了十類衣物,比如T恤,裙子,涼鞋,包,褲子等外觀樣式,只是比MNIST手寫識別更加困難。

圖為fashion-MNIST資料集的樣例
在Keras中,fashion-MNIST的匯入非常簡單:
from keras.datasets import fashion_mnist(X_test,y_test),
(X_train,y_train)=fashion_mnist.load_data()
注意到這裡,我們指定了測試集為60000個樣本,訓練集為10000個樣本,這實踐中當然是錯誤的。但是我們的目的是隻訓練那10000個樣本,並從中抽取30%作為驗證集,來達到比較模型優劣的目的。
如果我們保持模型不變,只改變資料,觀察在MNIST資料上表現良好的四個模型在fashion-MNIST上的表現:
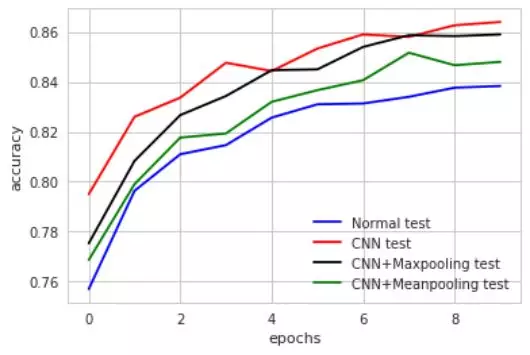
如圖,經過10個epochs,我們只觀察驗證集上的準確率對比,可以發現,全連線模型的準確率只有83%,CNN最好也只有86.5%。
接下來,我們嘗試在某一層使用多個大小的卷積核,在keras中,我們可以使用函式式模型,對同一個輸入分別採用不同的卷積,最後再將他們融合起來:
def conv_model_branch():
x=Input(shape=(28,28,1))
x2= Conv2D_bn(x,64,3,3)
branchx1= Conv2D_bn(x2,32,5,5)
branchx2= Conv2D_bn(x2,32,3,3)
branchx3=Conv2D_bn(x2,32,7,7)
branchx4=Conv2D_bn(x2,32,1,1)
x3=layers.concatenate([branchx1,branchx2,\
branchx3,branchx4],axis=-1)
x4=Flatten()(x3)
x5=Dense_bn(x4,32)
x6=Dropout(0.2)(x5)
y=Dense(10,activation='softmax')(x6)
model = Model(inputs=x, outputs=y)
model.compile(optimizer='SGD',
loss='categorical_crossentropy',
metrics=['accuracy'])
return(model)
我們在這裡分別建立了4個分支:
- branchx1是大小為5的卷積核
- branchx2是大小為3的卷積核
- branchx3是大小為7的卷積核
- branchx4是大小為1的卷積核
其中concatenate層就是一個將不同的分支按照某條軸串起來,以實現不同大小的卷積核輸出的融合。具體是怎麼串起來的呢?假如說A、B是矩陣,他們沿著行串起來,得到C,就會是:
A B C
a b c g h i a b c g h i
d e f j k l d e f j k l
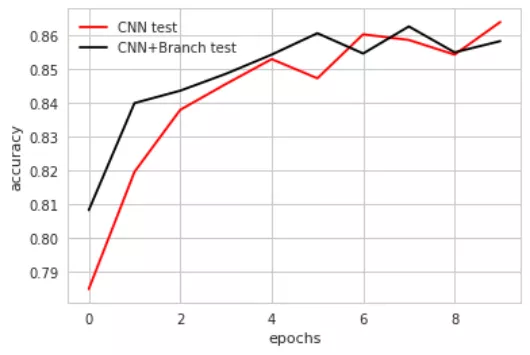
我們對這個簡單的模型進行訓練,同時訓練不使用複雜結構的CNN,將兩者驗證集上的表現對比,可以得到:
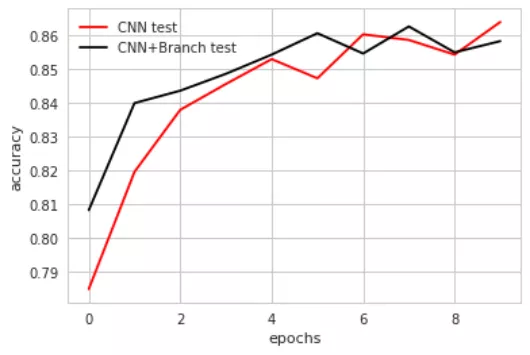
從圖中可以看出,新增多個尺寸卷積核的CNN與普通的直連的CNN相比,只是在訓練的開始階段表現優異,但隨著epochs的增多,效能上並沒有什麼優勢,一方面這可能是因為網路不夠龐大,表現為我們可能需要多進行幾次這樣的操作,另一方面則是因為我們在這裡只簡單的採取了多個尺寸卷積核的並行,而非對這些卷積核進行進一步的處理。

留言 點贊 發個朋友圈
我們一起分享AI學習與發展的乾貨
作者:唐僧不用海飛絲