動態規劃民科教程
這是我本人近段時間學習和練習動態規劃的總結,因為本人不是練過ACM的,所以自稱民科。文章末尾是一些有用的引用。
動態規劃(Dynamic Programming),一聽就是一個高大上的詞語,我們先來看看維基百科是怎麼說的:
動態規劃(英語:Dynamic programming,簡稱DP)是一種在數學、管理科學、電腦科學、經濟學和生物資訊學中使用的, 通過把原問題分解為相對簡單的子問題的方式求解複雜問題的方法。 動態規劃常常適用於有重疊子問題和最優子結構性質的問題,動態規劃方法所耗時間往往遠少於樸素解法。 動態規劃背後的基本思想非常簡單。大致上,若要解一個給定問題,我們需要解其不同部分(即子問題),再合併子問題的解以得出 原問題的解。 通常許多子問題非常相似,為此動態規劃法試圖僅僅解決每個子問題一次,從而減少計算量:一旦某個給定子問題的解已經算出, 則將其記憶化儲存,以便下次需要同一個子問題解之時直接查表。這種做法在重複子問題的數目關於輸入的規模呈指數增長時特別有用。
總結一下,動態規劃是:
- 一類問題的解法的總稱,而不是某個具體演算法的名稱
- 通過將原問題分解成子問題,並且記憶子問題的解,從而解出原問題
將一個問題分解成子問題,然後解決子問題並且記住結果,從而解決原問題。我們先忽略記住子問題的結果這一部分,這句話就變成 了:"將一個問題分解成子問題,然後解決子問題,從而解決原問題。"。是不是感覺似曾相識?在歸併排序中,我們就曾經用過這樣 的手法,先將陣列無限劃分,一直到只剩下一個元素,然後逐層往上歸併。我們就是這樣把原問題劃分成子問題,然後解決子問題, 最後原問題也得以解決的。
而這裡,我們用到了一個非常有助於抽象的工具,那就是遞迴。
遞迴
確切的來說,只要自身呼叫自身,就可以稱之為遞迴,但是本文中所說的遞迴,都是有把問題劃分成子問題,然後呼叫自身的。 比如,列印一個列表,我們可以這樣遞迴的列印:
def print_list(alist): if len(alist) == 0: return print(alist[0]) print_list(alist[1:]) if __name__ == "__main__": print_list([5, 4, 3, 2, 1])
我們先來看看上面的程式是怎麼工作的,首先,我們檢查基本情況,那就是列表是空的,那麼我們無需列印什麼,直接退出。否則, 我們把列表分割成兩份,一個 item,和一個列表,例如 [5, 4, 3, 2, 1] 就可以分割成 5 和 [4, 3, 2, 1] ,列印5之後, 我們再呼叫當前執行的這個函式自身,並且把 [4, 3, 2, 1] 作為引數,於是最後,就打印出了 5 4 3 2 1 。把上面的函式呼叫 畫出來,就是這樣:

通過逐次減小問題的規模,最終我們解決了原問題。
暴力遞迴
接下來我們看另外一個比較經典的問題:斐波那契數列 我們要求斐波那契數列中的第n位。經典的定義是:
fib :: Int -> Int fib 1 = 1 fib 2 = 1 fib n = (+) (fib $ n - 1) (fib $ n - 2)
我們把計算 fib(5) 的所有計算和遞迴所產生的子問題畫出來:

記憶化
如果仔細觀察,我們會發現,上圖的fibbnacci其實包含了很多重複計算,如下圖所示:
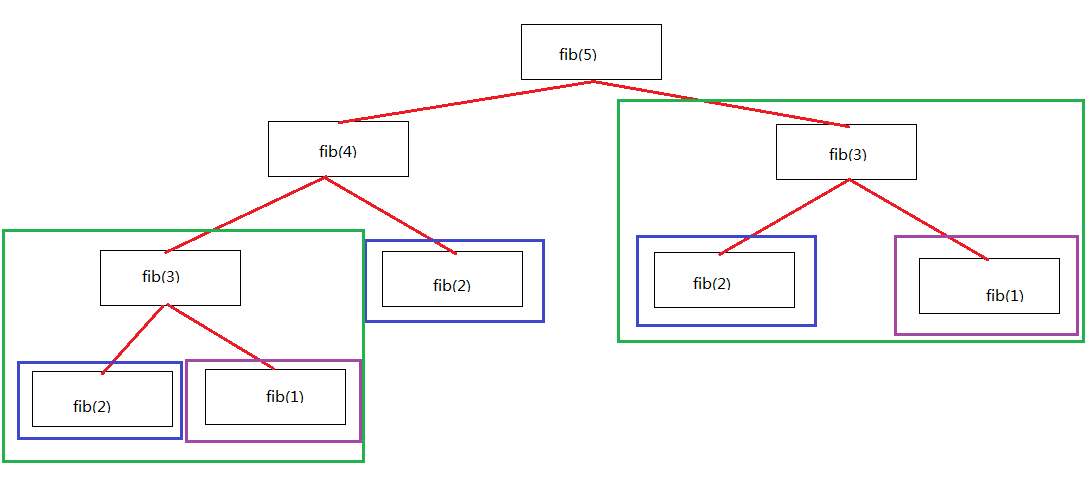
那如果我們通過把已經計算過的結果儲存下來,每次計算先檢查是否已經計算過,從而消除重複計算,速度會不會快很多呢?答案是會。 看下面的跑分:
In [1]: def fib1(n):
...:if n in (1, 2):
...:return 1
...:return fib1(n - 1) + fib1(n - 2)
...:
In [2]: %timeit fib1(20)
1.89 ms ± 39.2 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each)
In [3]: cache = {1: 1, 2: 1}
In [4]: def fib2(n):
...:if n in cache:
...:return cache[n]
...:cache[n] = fib2(n - 1) + fib2(n - 2)
...:return cache[n]
...:
In [5]: %timeit fib2(20)
181 ns ± 4.17 ns per loop (mean ± std. dev. of 7 runs, 10000000 loops each)
1.89ms 大概是 181ns 的10441倍!
告訴你一個不幸的訊息,這就是動態規劃。沒錯,就這麼簡單,這就是動態規劃,還記得我們上面說過的嗎?定義子問題,我們做到了 ,fibnacci原生的定義就已經告訴了我們子問題是什麼。解決子問題並且記住子問題的解,我們做到了,每次計算出結果後,先存到 cache裡,然後才返回。最終解決原問題。
嗯,遞迴,總感覺有點跳,是的,為什麼突然原問題就被解決了呢?要理解遞迴,需要一段時間,也許要仔細的思考。接下來我們看一 些真實的例子,讓我們的思維從迭代跳到遞迴。
遞迴的思考
遞迴這種技巧非常的巧妙,就好象我們從山頂看到山腳一樣的感覺,通常我們稱之為 "top-down",自頂向下。我們舉幾個常見的東西, 然後我們用遞迴的方式把他們分解:
- 字串可以看作是左邊一個字元,加右邊一個字串,比如 "hello" 可以是 'h' + "ello",而遞迴下去,"ello" = 'e' + "llo" ...
- 字串可以看作是左邊的一個字串,加右邊一個字元,比如 "hello" 可以是 "hell" + 'o',而遞迴下去,"hell" = "hel" + 'l'...
- 字串也可以看作是兩個字串拼接而成,通常我們會按照一定比例,比如1:1,那麼 "hello" 就可以看作是 "he" + "llo",遞迴下去, "he" = 'h' + 'e', "llo" = 'l' + "lo"...
- 連結串列我們可以看作是一個元素,加一個連結串列
- 樹我們可以看作是一個頂點,加兩棵樹
- 森林我們可以看作是一棵樹,加無數棵樹
- ...
解決了子問題,原問題就自然而然的得以解決,這叫遞迴跳躍。 更多可以參考 C程式設計的抽象思維,這本書很好的介紹了遞迴, 以及我們所需要克服的遞迴跳躍。
bottom-up
終於我們克服了遞迴跳躍,已經可以很自然的理解遞迴的思維了。不過,仔細想想,如果我們反其道而行之,從底層逐次拼接,自底 向上的思考會怎樣呢?兩個字串可以拼接成一個字串,一個字母和一個字串也可以拼接成一個新的字串。。。
我們試著這樣想想fibnacci,由數列我們可以推出規律,兩個相鄰的數列之和,就是下一個數字的值,那我們把它寫成程式,就是這樣的:
In [1]: def fib3(n): ...:left, right = 1, 1 ...:for i in range(2, n): ...:left, right = right, left + right ...:return right ...: In [2]: %timeit fib3(20) 1.1 µs ± 56.6 ns per loop (mean ± std. dev. of 7 runs, 1000000 loops each)
我個人更習慣,更容易想到的是 "top-down" 的形式,不過我的朋友更習慣,更容易想到的是 "bottom-up" 的形式,所以這可能是 不同的人的思維習慣造成的差異吧,我覺得各位喜歡就好,不過通常後者效率更高,因為遞迴不斷的呼叫函式是有一定開銷的,通常 如果想優化,可以把 "top-down" 改造成 "bottom-up"。
解題步驟
接下來我們框定一下解題步驟,或者說總結一下上面我們解題的思路:
- 定義子問題:字首型(比如"hello"分解為'h' + "ello"),字尾型(比如"hello"分解為"hell" + 'o')還是子序列型(比如"hello"分解為 "he"和"llo")?
- 猜測其中最可能的一種
- 開始對2進行嘗試
- 遞迴計算並且儲存結果
- 原問題得到解決,或者方法行不通,則跳到2嘗試另一種
上面的介紹中,我們的思路似乎一氣呵成,但是實際解題中,我們的想法可能會有很多種,而有可能很多種都是動態規劃並且都能得出 結果,所以這裡我們進行一些解題步驟的框定。其中最重要的步驟就是第二步,猜測。而且我們需要不停的猜測,如果這一種不行, 那麼就試試下一種,很多時候,直覺就會告訴我們會是哪種形式,然而擁有直覺的前提就是做足夠多的題目,深刻理解題目,那麼下次 遇到相似問題的時候,你的直覺就會冒出來了。
思路講解
接下來我們介紹幾道經典的動態規劃問題。我只寫出我的思路,程式碼就不貼了,因為就算你看懂了程式碼也無濟於事,最重要的是理解 思路。
最大連續子陣列和
輸入一個整型陣列,數組裡有正數也有負數。陣列中一個或連續的多個整陣列成一個子陣列。求所有子陣列的和的最大值。
- 對於陣列中的每一個元素,要麼是某個陣列中的一員,要麼是某個陣列中的起點,我們選擇更大的那個,便是答案。
編輯距離/最長公共子序列
ofollow,noindex" target="_blank">https://leetcode.com/problems/edit-distance/description/
對於兩個字串,把其中一個變成另外一個最少需要用多少步驟?
-
例如對於字串 "hello" 和 "el",我們要怎麼把一個變成另外一個呢?假設他們代號分別為a, b。i表示當前座標。
- 如果兩個字串的首字母相同,那麼我們繼續考慮兩個字串的其他部分就可以,即考慮a[i + 1:]和b[i + 1:]
- 如果不同,那麼考慮較長字串的下一個和較短字串的當前情況,即考慮a[i + 1:]和b[i:],或者是a[i:]和b[i + 1:],我們選取 這兩者中較長的那個,便是編輯步驟較少的那個
0-1揹包問題
我們有一個揹包,容量為S,有一堆寶石,每個的價值為W[i],體積為S[i]。求怎麼在有限的揹包容量帶走最高價值的寶石?
-
對於每一個寶石,我們可以選擇拿,或者不拿。但是,分為很多種情況:
- 沒有寶石
- 揹包容量為0
- 裝不下當前寶石
- 當前寶石,我們可以選擇拿,或者不拿
-
也許問題屬於字首型,我們從第一個寶石開始考慮,除去上面列出來的第一第二個是基本條件外,第三個,如果裝不下,那麼就 看下一個。第四個,如果裝得下,那麼我們選擇拿或者不拿中,較大的那一個結果。
爬樓梯
https://leetcode.com/problems/min-cost-climbing-stairs/description/
問題的定義是我們爬樓梯,每一步都會有代價,例如第i步代價為 cost[i] ,你可以從第0個臺階爬起,也可以從第一個臺階爬起,同時, 每次你可以跳一步,也可以跳兩步。求爬完樓梯的最小代價是多少。
- 我的想法是從最後一步開始考慮,這樣問題就變成了最後一步,加上除去最後一步之外,前面改怎麼跳
- 也許問題屬於字尾型
總結
最後我們總結一下動態規劃的解題相關的知識:
思路的起點
- 列舉前面一些例子,找出規律 - 從最後一步開始,然後想倒數第二步。。。 - 劃分成子序列會怎樣?能解決這個問題嗎?
遞迴的三種形式
- 字首型 - 字尾型 - 子序列型
快取的幾種常見形式
- 二維陣列:通常用於表示從i到j,例如cache[i][j]表示從i到j - 一維陣列:通常用於表示只需要儲存一個狀態的地方,例如和,差等 - 字典:一般和一維陣列類似
常見問題形式
- 求最大/最小值 - 求可不可行 - 求方案總數
我們用官方一些的話語來總結一下動態規劃,動態規劃的關鍵是狀態轉移方程,也就是刻畫如何將原問題縮減為子問題,或者將 子問題擴充為原問題。動態規劃的核心在於充分利用已經得出的結果,這也是狀態轉移的目的。
尾註中包括一些基本概念和資料,其中包括 Leetcode 中動態規劃類的題目,和 MIT的演算法公開課等。希望對大家都有所幫助。
- https://zh.wikipedia.org/wiki/%E5%8A%A8%E6%80%81%E8%A7%84%E5%88%92
- https://zh.wikipedia.org/wiki/%E6%96%90%E6%B3%A2%E9%82%A3%E5%A5%91%E6%95%B0%E5%88%97
- Leetcode動態規劃練習題: https://leetcode.com/tag/dynamic-programming/
- MIT演算法公開課: https://www.youtube.com/watch?v=OQ5jsbhAv_M&index=19&list=PLUl4u3cNGP61Oq3tWYp6V_F-5jb5L2iHb
- C程式設計的抽象思維: https://book.douban.com/subject/10754300/
- 揹包九講: https://github.com/tianyicui/pack