說說 Kafka 中的時間輪演算法
作者:Anur
連結:
https://my.oschina.net/anur/blog/2252539#h3_1
零、時間輪定義
簡單說說時間輪吧,它是一個高效的延時佇列,或者說定時器。實際上現在網上對於時間輪演算法的解釋很多,定義也很全,這裡引用一下朱小廝部落格裡出現的定義:
參考下圖,Kafka中的時間輪(TimingWheel)是一個儲存定時任務的環形佇列,底層採用陣列實現,陣列中的每個元素可以存放一個定時任務列表(TimerTaskList)。TimerTaskList是一個環形的雙向連結串列,連結串列中的每一項表示的都是定時任務項(TimerTaskEntry),其中封裝了真正的定時任務TimerTask。
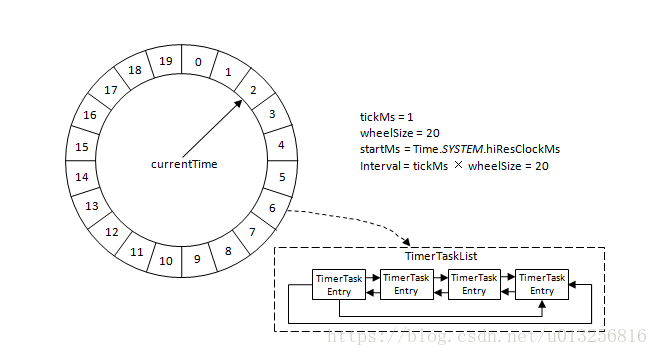
如果你理解了上面的定義,那麼就不必往下看了。但如果你第一次看到和我一樣懵比,並且有不少疑問,那麼這篇博文將帶你進一步瞭解時間輪,甚至理解時間輪演算法。
如果有興趣,可以去看看其他的定時器 你真的瞭解延時佇列嗎。博主認為,時間輪定時器最大的優點:
- 是任務的新增與移除,都是O(1)級的複雜度;
- 不會佔用大量的資源;
- 只需要有一個執行緒去推進時間輪就可以工作了。
我們將對時間輪做層層推進的解析:
一、為什麼使用環形佇列
假設我們現在有一個很大的陣列,專門用於存放延時任務。它的精度達到了毫秒級!那麼我們的延遲任務實際上需要將定時的那個時間簡單轉換為毫秒即可,然後將定時任務存入其中:
比如說當前的時間是2018/10/24 19:43:45,那麼就將任務存入Task[1540381425000],value則是定時任務的內容。

假如這個陣列長度達到了億億級,我們確實可以這麼幹。 那如果將精度縮減到秒級呢?我們也需要一個百億級長度的陣列。
先不說記憶體夠不夠,顯然你的定時器要這麼大的記憶體顯然很浪費。
當然如果我們自己寫一個map,並保證它不存在hash衝突問題,那也是完全可行的。(我不確定我的想法是否正確,如果錯誤,請指出)
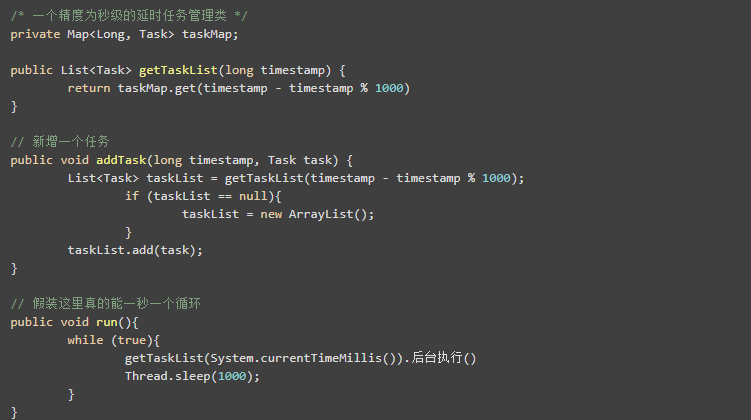
其實時間輪就是一個不存在hash衝突的資料結構
拋開其他疑問,我們看看手腕上的手錶(如果沒有去找個鐘錶,或者想象一個),是不是無論當前是什麼時間,總能用我們的錶盤去表示它(忽略精度)

就拿秒錶來說,它總是落在 0 - 59 秒,每走一圈,又會重新開始。
用虛擬碼模擬一下我們這個秒錶:

這樣,我們的時間總能落在0 - 59任意一個bucket上,就如同我們的秒鐘總是落在0 - 59刻度上一樣,這便是時間輪的環形佇列。
二、表示的時間有限
但是細心的小夥伴也會發現這麼一個問題:如果只能表示60秒內的定時任務應該怎麼儲存與取出,那是不是太有侷限性了?如果想要加入一小時後的延遲任務,該怎麼辦?
其實還是可以看一看鐘表,對於只有三個指標的表(一般的表)來說,最大能表示12個小時,超過了12小時這個範圍,時間就會產生歧義。如果我們加多幾個指標呢?比如說我們有秒針,分針,時針,上下午針,天針,月針,年針...... 那不就能表示很長很長的一段時間了?而且,它並不需要佔用很大的記憶體。
比如說秒針我們可以用一個長度為60的陣列來表示,分針也同樣可以用一個長度為60的陣列來表示,時針可以用一個長度為24的陣列來表示。那麼表示一天內的所有時間,只需要三個陣列即可。
動手來做吧,我們將這個資料結構稱作時間輪,tickMs表示一個刻度,比如說上面說的一秒。wheelSize表示一圈有多少個刻度,即上面說的60。interval表示一圈能表示多少時間,即 tickMs * wheelSize = 60秒。
overflowWheel表示上一層的時間輪,比如說,對於秒鐘來說,overflowWheel就表示分鐘,以此類推。

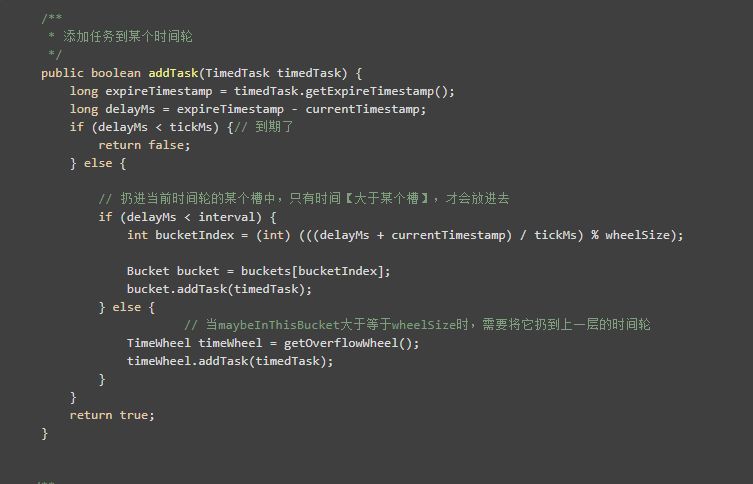
將任務新增到時間輪中十分簡單,對於每個時間輪來說,比如說秒級時間輪,和分級時間輪,都有它自己的過期槽。也就是delayMs < tickMs的時候。
新增延時任務的時候一共就這幾種情況:
1、時間到期
- 比如說有一個任務要在 16:29:07 執行,從秒級時間輪中來看,當我們的當前時間走到16:29:06的時候,則表示這個任務已經過期了。因為它的delayMs = 1000ms,小於了我們的秒級時間輪的tickMs(1000ms)。
- 比如說有一個任務要在 16:41:25 執行,從分級時間輪中來看,當我們的當前時間走到 16:41的時候(分級時間輪沒有秒針!它的最小精度是分鐘(一定要理解這一點)),則表示這個任務已經到期,因為它的delayMs = 25000ms,小於了我們的分級時間輪的tickMs(60000ms)。
2、時間未到期,且delayMs小於interval
對於秒級時間輪來說,就是延遲時間小於60s,那麼肯定能找到一個秒鐘槽扔進去。
3、時間未到期,且delayMs大於interval
對於妙級時間輪來說,就是延遲時間大於等於60s,這時候就需要藉助上層時間輪的力量了,很簡單的程式碼實現,就是拿到上層時間輪,然後類似遞迴一樣,把它扔進去。
比如說一個有一個延時為一年後的定時任務,就會在這個遞迴中不斷建立更上層的時間輪,直到找到滿足delayMs小於interval的那個時間輪。
這裡為了不把程式碼寫的那麼複雜,我們每一層時間輪的刻度都一樣,也就是秒級時間輪表示60秒,上面則表示60分鐘,再上面則表示60小時,再上層則表示60個60小時,再上層則表示60個60個60小時 = 216000小時。
也就是如果將最底層時間輪的tickMs(精度)設定為1000ms。wheelSize設定為60。那麼只需要5層時間輪,可表示的時間跨度已經長達24年(216000小時)。
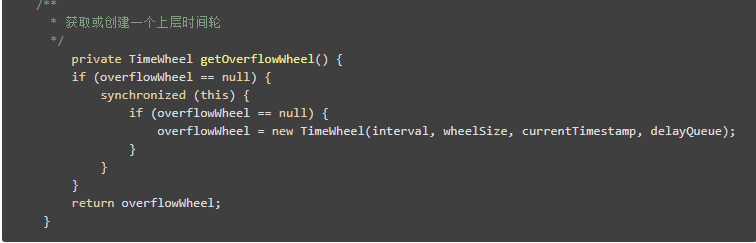
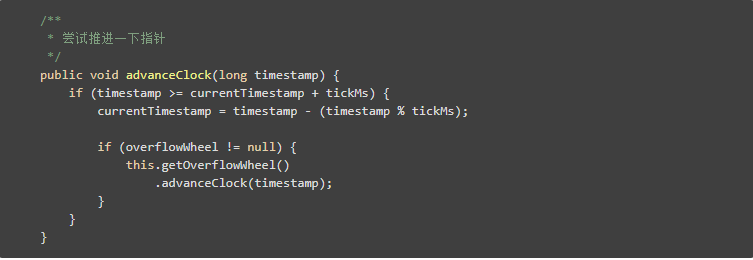
當然我們的時間輪還需要一個指標的推進機制,總不能讓時間永遠停留在當前吧?推進的時候,同時類似遞迴,去推進一下上一層的時間輪。
注意:要強調一點的是,我們這個時間輪更像是電子錶,它不存在時間的中間狀態,也就是精度這個概念一定要理解好。比如說,對於秒級時間輪來說,它的精度只能保證到1秒,小於1秒的,都會當成是已到期
對於分級時間輪來說,它的精度只能保證到1分,小於1分的,都會當成是已到期
三、對於高層時間輪來說,精度越來越不準,會不會有影響?
上面說到,分級時間輪,精度只有分鐘級,總不能延遲1秒的定時任務和延遲59秒的定時任務同時執行吧?
有這個疑問的同學很好!實際上很好解決,只需再入時間輪即可。比如說,對於分鐘級時間輪來說,delayMs為1秒和delayMs為59秒的都已經過期,我們將其取出,再扔進底層的時間輪不就可以了?
1秒的會被扔到秒級時間輪的下一個執行槽中,而59秒的會被扔到秒級時間輪的後59個時間槽中。
細心的同學會發現,我們的新增任務方法,返回的是一個bool
再倒回去好好看看,新增到最底層時間輪失敗的(我們只能直接操作最底層的時間輪,不能直接操作上層的時間輪),是不是會直接返回flase?對於再入失敗的任務,我們直接執行即可。

四、如何知道一個任務已經過期?
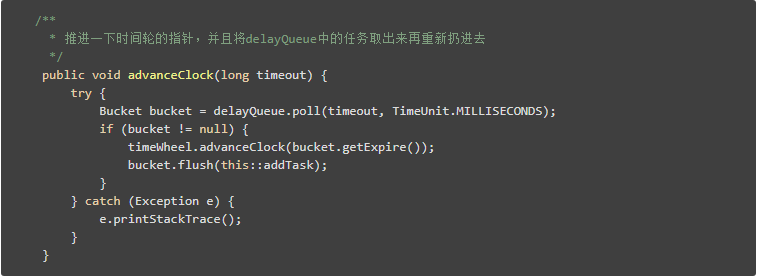
記得我們將任務儲存在槽中嘛?比如說秒級時間輪中,有60個槽,那麼一共有60個槽。如果時間輪共有兩層,也僅僅只有120個槽。我們只需將槽扔進一個delayedQueue之中即可。
我們輪詢地從delayedQueue取出已經過期的槽即可。(前面的所有程式碼,為了簡單說明,並沒有引入這個DelayQueue的概念,所以不用去上面翻了,並沒有。博主覺得...已經看到這裡了,應該很明白這個DelayQueue的意義了。)
其實簡單來說,實際上定時任務單單使用DelayQueue來實現,也是可以的,但是一旦任務的數量多了起來,達到了百萬級,千萬級,針對這個delayQueue的增刪,將非常的慢。
1、面向槽的delayQueue**
而對於時間輪來說,它只需要往delayQueue裡面扔各種槽即可,比如我們的定時任務長短不一,最長的跨度到了24年,這個delayQueue也僅僅只有300個元素。
2、處理過期的槽**
而這個槽到期後,也就是被我們從delayQueue中poll出來後,我們只需要將槽中的所有任務迴圈一次,重新加到新的槽中(新增失敗則直接執行)即可。
完整的時間輪GitHub,其實就是半抄半自己擼的Kafka時間輪簡化版 Timer#main 中模擬了六百萬個簡單的延時任務,執行的效率很高 ~
開源中國徵稿開始啦!
開源中國 www.oschina.net 是目前備受關注、具有強大影響力的開源技術社群,擁有超過 200 萬的開源技術精英。我們傳播開源的理念,推廣開源專案,為 IT 開發者提供一個發現、使用、並交流開源技術的平臺。