2019全球人工智慧應用創新峰會召開,解密最熱AI“芯”話題
2019年4月9日,第二屆全球人工智慧應用創新峰會在深圳五洲賓館舉行。本次峰會由深圳市科學技術協會、福田區科技創新局主辦,鯤雲科技、鯤雲人工智慧應用創新研究院和源創力創新中心承辦。在這場盛會上,AI領域的權威專家和知名企業家分別分享了人工智慧前沿技術突破和人工智慧落地應用的新進展。此外,作為峰會承辦方的鯤雲科技釋出了全球第一款基於資料流技術打造的通用人工智慧底層架構-定製資料流CAISA架構和端到端自動編譯工具鏈RainBuilder,實現了國內完全自主產權的AI晶片架構,為人工智慧演算法的快速應用落地提供了高效能算力支撐。

前沿交流,國際AI領域權威分享人工智慧前沿技術突破
作為年度重量級AI峰會,此次活動匯聚了政府領導、全球人工智慧領域頂尖學術大師、世界頂級科技企業、網際網路巨頭,產業界、投資界行業領袖,共同探討人工智慧實戰落地和產學研發展方向。整個峰會由政府致辭、主題演講和產業論壇三個環節組成。幾位人工智慧領域的國際權威分享了各自領域的最新進展和應用方向。

貢三元教授
IEEE終身會士Sun Yuan Kung(貢三元)教授是人工智慧神經網路學界大咖。在此次峰會上,他分享了反向傳播演算法問題及這些問題的解決策略。貢教授表示,AI1.0並不是使用神經網路,而是瞭解了知識,是基於專家知識的系統。但專家也有可能犯錯。Al2.0通過大資料多多少少解決了這些問題,卻依然無法學習架構。今年的圖靈獎授予了發明反向傳播演算法(即BP演算法)的Geoffrey Hinton教授,而BP演算法正是深度學習的基石之一。然而,它也存在不可解釋性和梯度消失等缺陷,會將深度學習網路變成了一個無法理解的“黑盒子”,並且使得網路深度增加時的學習能力降低,從而難以完成演算法的訓練。為了解決這一問題,貢教授團隊提出了神經網路3.0,可以學習內部神經元架構。貢教授還表示,AI領域中最重要的四個方面是晶片、演算法、應用和雲。相比於其他三項,國內目前在晶片方面比較薄弱。而將神經網路3.0應用到晶片中,能夠更好地提高晶片的效能並降低功耗。

陸永青院士
英國皇家工程院院士、帝國理工學院院士陸永青是鯤雲科技的聯合創始人兼CSO,是定製計算領域的國際權威。他進行了關於“定製計算的可驗證性”的主題分享。定製計算是可重構計算的一個重要分支,此次分享陳述了神經網路在執行時的功能準確性驗證。雖然神經網路已經在許多領域中得到了有效應用和落地,但其底層的執行機制導致深度學習網路很難用數學進行完全的解釋。為了避免神經網路輸入噪音而造成推斷結果的錯誤,陸院士提出了一種基於可重構硬體對推斷結果進行驗證的方法。這種驗證方法通過使用少量的硬體資源,在電路中對推斷過程的功能、資料和時序進行監控,從而有效地檢測出推斷過程中可能產生的錯誤。

魏少軍教授
IEEE會士、中國電子學會會士、清華大學教授魏少軍是中國晶片領域的領軍人物。此次,他進行了題為“軟體定義晶片:一種引向智慧計算的方式”的分享。他介紹了一個可通過軟體定義晶片的架構和設計。與傳統的CPU、FPGA和ASIC設計相比,該架構可實現軟體程式設計和硬體程式設計的高效結合。該架構設計允許硬體隨著軟體的變化實時動態地改變晶片功能。其核心設計原理是通過粗粒度的可重構架構來實現軟體對硬體運算元的呼叫。Thinker晶片便是基於此設計理念所實現的,該晶片將這種軟體可定義的硬體設計應用於AI演算法中,可顯著提高運算的效能、功效和演算法相容性。

Viktor K. Prasanna教授
IEEE會士、ACM會士、南加州大學教授Viktor K. Prasanna是FPGA邊緣計算領域的國際專家。他分享了一種輕量化FPGA計算架構在邊緣AI邊緣計算中的應用。該架構使用HIVE處理器和SHARP軟體框架,構建了一個基於FPGA的高效能AI加速器。其核心是通過對模型運算進行分割槽,從而實現對實際AI應用中有效資料區域的高速處理,避免了無效運算。除此之外,該FPGA加速器會在資料處理前,通過資料頻域轉換分析資料的稀疏策略,進一步實現有效資料的稀疏化處理並在系統執行時對模型進行剪枝、量化等效能優化,從而使得FPGA執行效能得到顯著提高。

Cristina Silvano教授
IEEE會士、米蘭理工大學計算機工程教授Cristina Silvano介紹了一種高效能集群系統(mARGOt)通過自動調節達到效能優化的方法。該優化過程可根據執行時的狀態,自動調整應用程式的執行引數,從而實現對系統性能的優化。通過歷史資料資訊,將應用中的關鍵效能引數提取出來並生成效能參考資料庫。當系統執行時,可根據具體場景資訊和參考資料對核心效能引數及核心執行狀態進行實時的動態調節,以達到系統對於場景的自適應,從而在實際場景中針對應用領域實現效能優化,例如新型藥物研發和智慧城市自適應導航系統等。

樊文飛院士
英國皇家學會會士、歐洲科學院院士、愛丁堡大學資訊學院主任教授樊文飛分享瞭如何將多種並行圖引擎應用於大資料分析場景。傳統並行的圖引擎優化難度大且成本較高,難以在實際場景中得到大規模應用。為了解決這一問題,樊院士將分散式的思想引入並行圖查詢引擎中,並以此為基礎開發了一種分散式並行圖處理系統。其核心思想是通過最小化重複的計算和操作以實現增量查詢。系統中採用了一種新的自適應非同步並行機制(AAP)調節不同程序之間的協作以提升整體效能。該系統應用於社交媒體、智庫、欺詐檢查等多種應用場景和領域。
重量專家,AI加速行業落地進行時
除了院士、會士嘉賓的學術分享以外,Intel PSG戰略市場總監的Tony Kau和浪潮人工智慧與產品總經理劉軍也分享了英特爾和浪潮在人工智慧的落地應用以及創新技術等方面的技術革新和新進展。

Intel PSG人工智慧、軟體和IP產品市場總監Tony Kau
隨著深度學習演算法的不斷髮展,AI對算力的需求也越來越高,為異構計算加速的發展提供了土壤。2018年底,英特爾在重慶成立了全球最大的FPGA創新中心,在AI領域動作有很多亮眼的動作,此次峰會上,Tony Kau就英特爾FPGA在人工智慧的落地應用進行了分享和交流,也分享了同鯤雲在AI加速應用和高校推廣等方面的深入合作。

浪潮人工智慧與高效能產品部總經理劉軍
作為國內最大的AI伺服器廠商,浪潮的市場佔有率為57%,擁有最強的AI計算產品陣列和端到端AI應用加速方案。這次劉軍總經理帶來了題為“AI計算創新與產業發展”的分享,探討人工智慧技術創新和浪潮的應用落地戰略。

此外,峰會還邀請到星瀚資本楊歌、雷鋒網麥廣煒、天津大學電子資訊學院副院長劉強、JWIPC副總經理劉迪科、CCE-YOCSEF深圳主席盧昱明等專家學者與鯤雲科技CTO蔡權雄博士就人工智慧晶片產業與生態落地等話題進行了探討。
鯤雲釋出全球首款通用底層AI架構-定製資料流CAISA架構

鯤雲科技創始人&CEO牛昕宇博士
鯤雲科技創始人&CEO牛昕宇博士在會上釋出了定製資料流CAISA2.0架構。依託創始團隊在資料流架構領域近三十年的積累,鯤雲的CAISA架構拋棄了傳統基於指令集的架構方式,是全球第一款基於資料流技術打造的通用人工智慧底層架構,可發揮90%以上的晶片峰值計算效能。同時,鯤雲還在會上釋出了針對資料流架構定製開發的RainBuilder編譯工具鏈。CAISA2.0架構可支援Tensorflow,Caffe等開源框架下開發的主流深度學習演算法的無縫遷移,無需使用者進行面向CAISA架構的程式設計。基於Arria10 SX160、SX660、GX1150,Straix10 GX2800系列的FPGA加速卡已完成開發並應用於產品落地中。

定製資料流CAISA2.0架構
隨著人工智慧技術的深入發展,對人工智慧晶片的算力提出了更高的要求,算力成為了決定演算法落地的重中之重。尤其是在雲端計算、自動駕駛、安防工業等領域,算力的提升更是能夠直接帶來更多的使用者量、更多的前端裝置智慧升級和更安全的自動駕駛汽車。
正如圖靈獎得主John Hennessey和 David Patterson在圖靈獎頒獎典禮所言,未來十年,隨著摩爾定律逐步飽和,人工智慧晶片的峰值算力將逐步趨近飽和,而架構效率將成為晶片效能的決定因素,未來十年將是計算架構的“黃金十年”。
鯤雲科技自主研發的CAISA2.0架構以及RainBuilder編譯工具鏈,沒有采用主流計算機架構下大規模並行指令集設計的思路,通過完全不同的資料流架構突破底層架構的效率瓶頸,最大化發揮底層硬體的效率,在同等峰值晶片效能情況下可以為人工智慧應用提供更高的算力支撐。
要實現更快的AI應用落地,滿足不同演算法開發的需求,需要一個可以相容各類演算法框架和方便快捷實現演算法到硬體寫入的編譯工具。為了降低使用門檻,鯤雲釋出了端到端自動編譯工具鏈RainBuilder。這是一款針對深度學習演算法優化加速的開發工具鏈。依託於CAISA架構的高效能特性,RainBuilder提供從演算法模型到晶片級演算法部署的一整套開發套件。該套件主要由Compiler和Runtime兩部分組成,其中Compiler包含了一系列命令列介面,支援主流AI開發框架模型的解析和優化,並將模型轉化為適用於CAISA架構的中間表達和資料。Runtime以Compiler生成的中間表達和資料為輸入,為使用者提供了豐富易用的開發介面以完成對底層AI晶片硬體的高效應用。
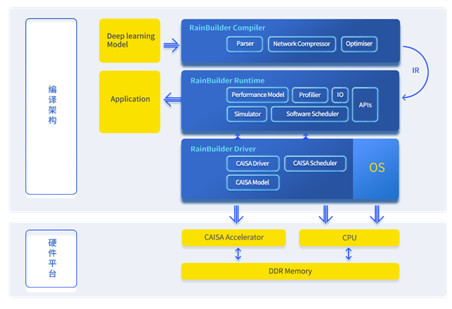
RainBuilder端到端自動編譯工具鏈
RainBuilder使用過程非常簡單便捷,使用者無需對於底層硬體有深入的瞭解,即可快速開發適用於AI專用晶片的演算法方案。從訓練好的模型檔案,只需兩步即可實現整個神經網路的推演。第一步,呼叫Compiler的命令列介面完成模型的離線準備,對於一個模型,該步驟只需進行一次。Compiler提供了一套端到端的優化流程,包括模型解析、冗餘節點裁剪、節點融合、模型量化壓縮等。第二步,使用者只需編寫針對特定演算法的前後處理函式,Runtime會自動完成演算法模型對於CAISA架構的高效呼叫。Runtime中包含了大量針對CAISA架構的深層優化,如硬體資源調配、執行時資源排程、軟硬體並行、異常處理等。另外,RainBuilder通過支援使用者自定義運算元實現了對於不同演算法的高拓展性。使用者只需根據提供的介面即可完成自定義模組的實現,RainBuilder會自動將自定義運算元整合進計算圖中,並針對其特點完成相應的計算優化。