Spring Boot和Kafka實戰自定義複雜配置示例
這篇部落格文章展示瞭如何配置Spring Kafka和Spring Boot以使用JSON傳送訊息並以多種格式接收它們:JSON,純字串或位元組陣列。基於此配置,您還可以將Kafka生成器從傳送JSON切換到其他序列化方法。
此示例應用程式還演示了同一消費組中三個Kafka消費者的使用情況,因此訊息在三者之間進行負載平衡。每個消費者實現不同的反序列化方法。
您可以瞭解一些Kafka概念,如Consumer Group和Topic分割槽。
多個消費者
要更好地理解配置,請檢視下圖。如您所見,我們建立了一個包含三個分割槽的Kafka主題。在消費者方面,只有一個應用程式,但它實現了具有相同group.id 屬性的三個Kafka消費者。
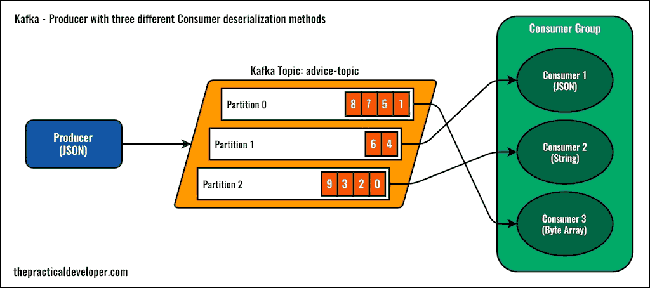
當我們啟動應用程式時,Kafka會為每個消費者分配一個不同的分割槽。消費者組將以負載平衡的方式接收訊息。在這篇文章的後面,如果我們讓它們具有不同的組識別符號,你會看到有什麼區別(如果你熟悉Kafka,你可能知道結果)。
示例用例
我們要構建的邏輯很簡單。每次我們呼叫指定REST端點hello,應用程式將生成可配置數量的訊息,並使用序列號作為Kafka金鑰將它們傳送到同一主題,等待消費所有訊息後返回Hello Kafka!
設定Kafka和Spring Boot
首先,您需要有一個正在執行的Kafka叢集才能連線。對於這個應用程式,我將在單個節點中使用docker-compose和Kafka。這顯然遠不是一個生產配置,但它足以滿足這篇文章的目標。
以下是docker-compose.yml配置
version: '2' services: zookeeper: image: wurstmeister/zookeeper ports: - <font>"2181:2181"</font><font> kafka: image: wurstmeister/kafka ports: - </font><font>"9092:9092"</font><font> environment: KAFKA_ADVERTISED_HOST_NAME: 127.0.0.1 KAFKA_ZOOKEEPER_CONNECT: zookeeper:2181 KAFKA_AUTO_CREATE_TOPICS_ENABLE: 'false' </font>
請注意,我將Kafka配置為不 自動建立主題(最後一行配置)。我們將在Spring Boot應用程式建立我們的主題,因為我們想要傳遞一些自定義配置。如果你想玩玩這些Docker影象(例如使用多個節點),請檢視wurstmeister/zookeeper影象ofollow,noindex" target="_blank">文件
要啟動Kafka和Zookeeper容器,只要在上述配置目錄下執行 docker-compose up
獲取SpringBoot應用程式骨架的最簡單方法是到start.spring.io ,使用使用YAML進行配置配置application.yml:
spring: kafka: consumer: group-id: tpd-loggers auto-offset-reset: earliest # change <b>this</b> property <b>if</b> you are using your own # Kafka cluster or your Docker IP is different bootstrap-servers: localhost:9092 tpd: topic-name: advice-topic messages-per-request: 10
第一部分屬性是Spring Kafka配置:
- Kafka的組標識 group-id
- auto-offset-reset 屬性設定為earliest,這意味著當消費者沒有發現偏移量(指標)時,消費者將開始從最早的訊息中讀取訊息。
- 第三行用於連線Kafka的伺服器,在這種情況下,如果您使用單節點配置,則是唯一可用的伺服器。請注意,如果使用預設值 localhost:9092,則此屬性是多餘的 。
第二部分是特定於應用程式的自定義配置。我們定義Kafka主題名稱以及每次執行HTTP REST請求時要傳送的訊息數。
Message類
這是我們將用作Kafka訊息的Java類。這裡沒有什麼複雜的,只是@JsonProperty 在建構函式引數中帶有註釋的不可變類, 因此Jackson可以正確地反序列化它。
<b>import</b> com.fasterxml.jackson.annotation.JsonProperty;
<b>public</b> <b>class</b> PracticalAdvice {
<b>private</b> <b>final</b> String message;
<b>private</b> <b>final</b> <b>int</b> identifier;
<b>public</b> PracticalAdvice(@JsonProperty(<font>"message"</font><font>) <b>final</b> String message,
@JsonProperty(</font><font>"identifier"</font><font>) <b>final</b> <b>int</b> identifier) {
<b>this</b>.message = message;
<b>this</b>.identifier = identifier;
}
<b>public</b> String getMessage() {
<b>return</b> message;
}
<b>public</b> <b>int</b> getIdentifier() {
<b>return</b> identifier;
}
@Override
<b>public</b> String toString() {
<b>return</b> </font><font>"PracticalAdvice::toString() {"</font><font> +
</font><font>"message='"</font><font> + message + '\'' +
</font><font>", identifier="</font><font> + identifier +
'}';
}
}
</font>
Spring Boot中的Kafka Producer配置
為了簡化應用程式,我們將在Spring Boot類中新增配置。最後,我們希望在此處包含生產者和消費者配置,並使用三種不同的變體進行反序列化。請記住,您可以在GitHub儲存庫中 找到完整的原始碼。
首先,讓我們關注Producer配置:
@SpringBootApplication
<b>public</b> <b>class</b> KafkaExampleApplication {
<b>public</b> <b>static</b> <b>void</b> main(String[] args) {
SpringApplication.run(KafkaExampleApplication.<b>class</b>, args);
}
@Autowired
<b>private</b> KafkaProperties kafkaProperties;
@Value(<font>"${tpd.topic-name}"</font><font>)
<b>private</b> String topicName;
</font><font><i>// Producer configuration</i></font><font>
@Bean
<b>public</b> Map<String, Object> producerConfigs() {
Map<String, Object> props =
<b>new</b> HashMap<>(kafkaProperties.buildProducerProperties());
props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,
StringSerializer.<b>class</b>);
props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,
JsonSerializer.<b>class</b>);
<b>return</b> props;
}
@Bean
<b>public</b> ProducerFactory<String, Object> producerFactory() {
<b>return</b> <b>new</b> DefaultKafkaProducerFactory<>(producerConfigs());
}
@Bean
<b>public</b> KafkaTemplate<String, Object> kafkaTemplate() {
<b>return</b> <b>new</b> KafkaTemplate<>(producerFactory());
}
@Bean
<b>public</b> NewTopic adviceTopic() {
<b>return</b> <b>new</b> NewTopic(topicName, 3, (<b>short</b>) 1);
}
}
</font>
在此配置中,我們將設定應用程式的兩個部分:
-
KafkaTemplate例項,這是我們將使用它將訊息傳送到卡夫卡。我們不想使用預設版本,因此我們需要在Spring的應用程式上下文中注入我們的自定義這個例項版本。
- 我們鍵入(使用泛型)KafkaTemplate以具有普通的String鍵和Object作為值。將Object作為值的原因是我們希望使用相同的模板傳送多個物件型別。KafkaTemplate接受我們在配置中建立的ProducerFactory作為引數。
- 我們使用的ProducerFactory是預設的,但是我們需要在這裡顯式配置,因為我們想要傳遞我們的自定義生成器配置。
- Producer Configuration是一個簡單的鍵值對映。我們使用預設屬性@Autowired 來獲取 KafkaProperties bean,然後構建我們的map,傳遞生成器的預設值,並覆蓋預設的Kafka鍵和值序列化器。生產者將使用Kafka庫將鍵序列化為字串,StringSerializer 並且將對值執行相同的操作,但這次使用JSON JsonSerializer,在本例中由Spring Kafka提供。
- 我們將要使用的Kafka主題。通過注入一個NewTopic 例項,我們指示Kafka的AdminClient bean(已經在上下文中)建立一個具有給定配置的主題。第一個引數是名稱(advice-topic,來自app配置),第二個是分割槽數量(3),第三個引數是複製因子(一個,因為我們無論如何都使用單個節點)。
關於Java的Kafka Serializers和Deserializers
Strings 的核心Kafka庫(javadoc )中提供了一些基本的Serializer ,所有型別的陣列類和位元組陣列,以及Spring Kafka(javadoc )提供的JSON類。
最重要的是,您可以通過實現Serializer or ExtendedSerializer或其相應的反序列化版本來建立自己的序列化器和反序列化器。這為您提供了很大的靈活性,可以優化通過Kafka傳輸的資料量。正如您在這些介面中看到的那樣,Kafka使用普通位元組陣列,因此,無論您使用何種複雜型別,都需要將其轉換為byte[]。
知道這一點,你可能想知道為什麼有人想要在Kafka上使用JSON。由於您將物件轉換為JSON然後轉換為位元組陣列,因此效率非常低。但是你必須考慮這樣做有兩個主要優點:
- JSON比人類更可讀,而不是位元組陣列。如果您想除錯或分析Kafka主題的內容,那麼它將比檢視裸位元組更簡單。
- JSON是標準,而預設位元組陣列序列化器依賴於程式語言實現。因此,如果要使用來自多種程式語言的訊息,則需要在所有這些語言中複製(反)序列化器邏輯。
另一方面,如果您擔心Kafka中的流量負載,儲存或(反)序列化速度,您可能需要選擇位元組陣列,甚至可以選擇自己的序列器/解串器實現。
使用Spring Boot和Kafka傳送訊息
我們建立一個Rest Controller,並在KafkaTemplate 請求端點時通過注入來生成一些JSON訊息。
這是控制器的第一個實現,僅包含產生訊息的邏輯。
@RestController
<b>public</b> <b>class</b> HelloKafkaController {
<b>private</b> <b>static</b> <b>final</b> Logger logger =
LoggerFactory.getLogger(HelloKafkaController.<b>class</b>);
<b>private</b> <b>final</b> KafkaTemplate<String, Object> template;
<b>private</b> <b>final</b> String topicName;
<b>private</b> <b>final</b> <b>int</b> messagesPerRequest;
<b>private</b> CountDownLatch latch;
<b>public</b> HelloKafkaController(
<b>final</b> KafkaTemplate<String, Object> template,
@Value(<font>"${tpd.topic-name}"</font><font>) <b>final</b> String topicName,
@Value(</font><font>"${tpd.messages-per-request}"</font><font>) <b>final</b> <b>int</b> messagesPerRequest) {
<b>this</b>.template = template;
<b>this</b>.topicName = topicName;
<b>this</b>.messagesPerRequest = messagesPerRequest;
}
@GetMapping(</font><font>"/hello"</font><font>)
<b>public</b> String hello() throws Exception {
latch = <b>new</b> CountDownLatch(messagesPerRequest);
IntStream.range(0, messagesPerRequest)
.forEach(i -> <b>this</b>.template.send(topicName, String.valueOf(i),
<b>new</b> PracticalAdvice(</font><font>"A Practical Advice"</font><font>, i))
);
latch.await(60, TimeUnit.SECONDS);
logger.info(</font><font>"All messages received"</font><font>);
<b>return</b> </font><font>"Hello Kafka!"</font><font>;
}
}
</font>
在建構函式中,我們傳遞一些配置引數和我們自定義的KafkaTemplate,以傳送String鍵和JSON值。然後,當API客戶端請求/hello 端點時,我們傳送10條訊息(這是配置值),然後我們阻止執行緒最多60秒。鎖存器解鎖後,我們將訊息返回Hello Kafka! 給客戶端。
這整個鎖定的想法不是在實際應用程式中看到的模式,但它對於這個例子來說是好的。這樣,您可以檢查收到的郵件數量。如果您願意,可以在接收訊息之前刪除鎖存器並返回“Hello Kafka!”訊息。
Kafka消費者配置
正如前面在本文中所提到的,我們希望演示使用Spring Boot和Spring Kafka進行反序列化的不同方法,同時瞭解當多個消費者屬於同一個消費者組時,多個消費者如何以負載均衡的方式工作。
@SpringBootApplication
<b>public</b> <b>class</b> KafkaExampleApplication {
<b>public</b> <b>static</b> <b>void</b> main(String[] args) {
SpringApplication.run(KafkaExampleApplication.<b>class</b>, args);
}
@Autowired
<b>private</b> KafkaProperties kafkaProperties;
@Value(<font>"${tpd.topic-name}"</font><font>)
<b>private</b> String topicName;
</font><font><i>// Producer configuration</i></font><font>
</font><font><i>// omitted...</i></font><font>
</font><font><i>// Consumer configuration</i></font><font>
</font><font><i>// If you only need one kind of deserialization, you only need to set the</i></font><font>
</font><font><i>// Consumer configuration properties. Uncomment this and remove all others below.</i></font><font>
</font><font><i>//@Bean</i></font><font>
</font><font><i>//public Map<String, Object> consumerConfigs() {</i></font><font>
</font><font><i>//Map<String, Object> props = new HashMap<>(</i></font><font>
</font><font><i>//kafkaProperties.buildConsumerProperties()</i></font><font>
</font><font><i>//);</i></font><font>
</font><font><i>//props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG,</i></font><font>
</font><font><i>//StringDeserializer.class);</i></font><font>
</font><font><i>//props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG,</i></font><font>
</font><font><i>//JsonDeserializer.class);</i></font><font>
</font><font><i>//props.put(ConsumerConfig.GROUP_ID_CONFIG,</i></font><font>
</font><font><i>//"tpd-loggers");</i></font><font>
</font><font><i>//</i></font><font>
</font><font><i>//return props;</i></font><font>
</font><font><i>//}</i></font><font>
@Bean
<b>public</b> ConsumerFactory<String, Object> consumerFactory() {
<b>final</b> JsonDeserializer<Object> jsonDeserializer = <b>new</b> JsonDeserializer<>();
jsonDeserializer.addTrustedPackages(</font><font>"*"</font><font>);
<b>return</b> <b>new</b> DefaultKafkaConsumerFactory<>(
kafkaProperties.buildConsumerProperties(), <b>new</b> StringDeserializer(), jsonDeserializer
);
}
@Bean
<b>public</b> ConcurrentKafkaListenerContainerFactory<String, Object> kafkaListenerContainerFactory() {
ConcurrentKafkaListenerContainerFactory<String, Object> factory =
<b>new</b> ConcurrentKafkaListenerContainerFactory<>();
factory.setConsumerFactory(consumerFactory());
<b>return</b> factory;
}
</font><font><i>// String Consumer Configuration</i></font><font>
@Bean
<b>public</b> ConsumerFactory<String, String> stringConsumerFactory() {
<b>return</b> <b>new</b> DefaultKafkaConsumerFactory<>(
kafkaProperties.buildConsumerProperties(), <b>new</b> StringDeserializer(), <b>new</b> StringDeserializer()
);
}
@Bean
<b>public</b> ConcurrentKafkaListenerContainerFactory<String, String> kafkaListenerStringContainerFactory() {
ConcurrentKafkaListenerContainerFactory<String, String> factory =
<b>new</b> ConcurrentKafkaListenerContainerFactory<>();
factory.setConsumerFactory(stringConsumerFactory());
<b>return</b> factory;
}
</font><font><i>// Byte Array Consumer Configuration</i></font><font>
@Bean
<b>public</b> ConsumerFactory<String, byte[]> byteArrayConsumerFactory() {
<b>return</b> <b>new</b> DefaultKafkaConsumerFactory<>(
kafkaProperties.buildConsumerProperties(), <b>new</b> StringDeserializer(), <b>new</b> ByteArrayDeserializer()
);
}
@Bean
<b>public</b> ConcurrentKafkaListenerContainerFactory<String, byte[]> kafkaListenerByteArrayContainerFactory() {
ConcurrentKafkaListenerContainerFactory<String, byte[]> factory =
<b>new</b> ConcurrentKafkaListenerContainerFactory<>();
factory.setConsumerFactory(byteArrayConsumerFactory());
<b>return</b> factory;
}
}
</font>
這種配置可能看起來很繁瑣,但考慮到為了演示這三種類型的反序列化,我們重複了三次建立ConsumerFactory和KafkaListenerContainerFactory例項,以便我們可以在消費者中切換它們。
配置消費者的基本步驟是:
- 以類似Producer的方式設定Consumer屬性。我們可以跳過此步驟,因為我們需要的唯一配置是Spring Boot屬性檔案中指定的Group ID,以及我們將在建立自定義消費者和KafkaListener工廠,從而實現自定義的鍵和值反序列化器。如果您只需要一個配置,意味著始終使用相同型別的Key和Value反序列化器,那麼被註釋掉的程式碼塊符合你這一需求,可將反序列化器型別調整為你要使用的型別。
- 要使用的KafkaListenerContainerFactory就要建立ConsumerFactory, 我們建立三個,在每種情況下將反序列化器切換為1)JSON反序列化器,2)字串反序列化器和3)位元組陣列反序列化器。[list=1]
- 請注意,在建立JSON反序列化器之後,我們將包含一個額外的步驟來指定我們信任所有包。如果需要,您可以在應用程式中對其進行微調。如果我們不這樣做,我們將收到一條錯誤訊息,上面寫著:java.lang.IllegalArgumentException: The class [] is not in the trusted packages。
使用先前配置的Consumer Factory構造KafkaListenerContainerFactory(併發容器工廠)。同樣,我們這樣做三次,每個例項使用不同的一個。
使用Spring Boot和Kafka以JSON,String和byte []格式接收訊息
現在是時候展示Kafka消費者的樣子了。我們將使用@KafkaListener 註釋,因為它簡化了過程並負責對傳遞的Java型別進行反序列化。
@RestController
<b>public</b> <b>class</b> HelloKafkaController {
<b>private</b> <b>static</b> <b>final</b> Logger logger =
LoggerFactory.getLogger(HelloKafkaController.<b>class</b>);
<b>private</b> <b>final</b> KafkaTemplate<String, Object> template;
<b>private</b> <b>final</b> String topicName;
<b>private</b> <b>final</b> <b>int</b> messagesPerRequest;
<b>private</b> CountDownLatch latch;
<b>public</b> HelloKafkaController(
<b>final</b> KafkaTemplate<String, Object> template,
@Value(<font>"${tpd.topic-name}"</font><font>) <b>final</b> String topicName,
@Value(</font><font>"${tpd.messages-per-request}"</font><font>) <b>final</b> <b>int</b> messagesPerRequest) {
<b>this</b>.template = template;
<b>this</b>.topicName = topicName;
<b>this</b>.messagesPerRequest = messagesPerRequest;
}
@GetMapping(</font><font>"/hello"</font><font>)
<b>public</b> String hello() throws Exception {
latch = <b>new</b> CountDownLatch(messagesPerRequest);
IntStream.range(0, messagesPerRequest)
.forEach(i -> <b>this</b>.template.send(topicName, String.valueOf(i),
<b>new</b> PracticalAdvice(</font><font>"A Practical Advice"</font><font>, i))
);
latch.await(60, TimeUnit.SECONDS);
logger.info(</font><font>"All messages received"</font><font>);
<b>return</b> </font><font>"Hello Kafka!"</font><font>;
}
@KafkaListener(topics = </font><font>"advice-topic"</font><font>, clientIdPrefix = </font><font>"json"</font><font>,
containerFactory = </font><font>"kafkaListenerContainerFactory"</font><font>)
<b>public</b> <b>void</b> listenAsObject(ConsumerRecord<String, PracticalAdvice> cr,
@Payload PracticalAdvice payload) {
logger.info(</font><font>"Logger 1 [JSON] received key {}: Type [{}] | Payload: {} | Record: {}"</font><font>, cr.key(),
typeIdHeader(cr.headers()), payload, cr.toString());
latch.countDown();
}
@KafkaListener(topics = </font><font>"advice-topic"</font><font>, clientIdPrefix = </font><font>"string"</font><font>,
containerFactory = </font><font>"kafkaListenerStringContainerFactory"</font><font>)
<b>public</b> <b>void</b> listenasString(ConsumerRecord<String, String> cr,
@Payload String payload) {
logger.info(</font><font>"Logger 2 [String] received key {}: Type [{}] | Payload: {} | Record: {}"</font><font>, cr.key(),
typeIdHeader(cr.headers()), payload, cr.toString());
latch.countDown();
}
@KafkaListener(topics = </font><font>"advice-topic"</font><font>, clientIdPrefix = </font><font>"bytearray"</font><font>,
containerFactory = </font><font>"kafkaListenerByteArrayContainerFactory"</font><font>)
<b>public</b> <b>void</b> listenAsByteArray(ConsumerRecord<String, byte[]> cr,
@Payload byte[] payload) {
logger.info(</font><font>"Logger 3 [ByteArray] received key {}: Type [{}] | Payload: {} | Record: {}"</font><font>, cr.key(),
typeIdHeader(cr.headers()), payload, cr.toString());
latch.countDown();
}
<b>private</b> <b>static</b> String typeIdHeader(Headers headers) {
<b>return</b> StreamSupport.stream(headers.spliterator(), false)
.filter(header -> header.key().equals(</font><font>"__TypeId__"</font><font>))
.findFirst().map(header -> <b>new</b> String(header.value())).orElse(</font><font>"N/A"</font><font>);
}
}
</font>
這裡有三個消費者。首先,讓我們描述@KafkaListener 註釋的引數:
- 所有消費者都使用相同的主題advice-topic。此引數是必需的。
- 引數clientIdPrefix 是可選的。我在這裡使用它,讓日誌更人性化。您將知道哪個消費者通過其名稱字首做什麼。卡夫卡將附加一個這個字首的數字。
- containerFactory 引數是可選的,您還可以依賴命名約定。如果不指定它,它將查詢具有名稱的bean kafkaListenerContainerFactory,這也是Spring Boot在自動配置Kafka時使用的預設名稱。您也可以使用相同的名稱覆蓋它(儘管對於不瞭解約定的人來說它看起來很神奇)。我們需要明確地設定它,因為我們想為每個監聽器使用不同的一個,以便能夠使用不同的反序列化器。
請注意,傳遞給所有消費者的第一個引數是相同的:一個 ConsumerRecord和@Payload,如果我們使用第一個,則第二個 是多餘的。我們可以訪問ConsumerRecord的方法value() 獲得Payload,但我這裡寫在這裡,讓你看到它是多麼簡單直接通過反序列化得到的Payload。
Kafka中的TypeId標頭
標頭 __TypeId__預設情況下由Kafka庫自動設定。我這裡使用工具方法typeIdHeader 獲得字串,因為從ConsumerRecord的toString() 方法只能看到位元組組輸出。
TypeId標頭可用於反序列化,因此您可以找到要將資料對映到的型別。但是JSON反序列化卻不需要它,因為這個特殊的反序列化器是由Spring團隊製作,並且它們從方法的引數中推斷出型別。
執行
現在我們完成了Kafka生產者和消費者,我們可以執行Kafka和Spring Boot應用程式:
$ docker-compose up -d
Starting kafka-example_zookeeper_1 ... done
Starting kafka-example_kafka_1 ... done
$ mvn spring-boot:run
pring Boot應用程式啟動,消費者在Kafka中註冊,Kafka為它們分配了一個分割槽。我們使用三個分割槽配置主題,因此每個消費者都會分配其中一個分割槽。
[Consumer clientId=string-0, groupId=tpd-loggers] Successfully joined group with generation 28 <p>[Consumer clientId=string-0, groupId=tpd-loggers] Setting newly assigned partitions [advice-topic-2] <p>[Consumer clientId=bytearray-0, groupId=tpd-loggers] Successfully joined group with generation 28 <p>[Consumer clientId=bytearray-0, groupId=tpd-loggers] Setting newly assigned partitions [advice-topic-0] <p>[Consumer clientId=json-0, groupId=tpd-loggers] Successfully joined group with generation 28 <p>[Consumer clientId=json-0, groupId=tpd-loggers] Setting newly assigned partitions [advice-topic-1] partitions assigned: [advice-topic-1] partitions assigned: [advice-topic-2] partitions assigned: [advice-topic-0]
我們現在可以嘗試對服務進行HTTP呼叫。您可以使用瀏覽器curl,例如:
curl localhost:8080/hello
注意日誌中的輸出。
以上原始碼:Kafka and Spring Boot Example .
解釋
Kafka對訊息的key進行雜湊化(key是一個簡單的字串識別符號),並根據key將訊息放入不同的分割槽。每個使用者在其分配的分割槽中獲取訊息,並使用其反序列化器將其轉換為Java物件。請記住,我們的生產者總是傳送JSON值。
正如您在日誌中看到的,每個反序列化器都設法完成其任務,因此String消費者列印原始JSON訊息,位元組陣列消費者顯示JSON字串的位元組表示,JSON反序列化器使用Java型別對映器進行轉換到原來的類PracticalAdvice。您可以檢視記錄的ConsumerRecord,您將看到標題,指定的分割槽,偏移量等。
這就是你如何使用Spring Boot和Kafka傳送和接收JSON訊息。我希望您發現本指南很有用,下面您有一些程式碼變體,以便您可以更多地瞭解Kafka的工作原理。
多次請求/hello
發出一些請求,然後檢視訊息如何跨分割槽分佈。具有相同金鑰的Kafka訊息始終放在相同的分割槽中。當您希望確保指定使用者、程序或正在處理的任何邏輯的所有訊息都由同一消費者以與生成時相同的順序接收時,此功能非常有用(在事件溯源EventSourcing時實現事件順序,從而實現事務一致性很需要),這裡就不考慮負載平衡了。
減少分割槽數量
首先,確保重新啟動Kafka,這樣您就可以放棄以前的配置。
然後,在應用程式中重新定義主題,使其只有2個分割槽:
@Bean
<b>public</b> NewTopic adviceTopic() {
<b>return</b> <b>new</b> NewTopic(topicName, 2, (<b>short</b>) 1);
}
現在,再次執行應用程式並向/hello 端點發出請求。
結果:其中一個消費者沒有收到任何訊息。這是預期的行為,因為同一消費者組中沒有可用的分割槽(我們只設置了2個分割槽)。
更改一個消費者的組識別符號
保留上一個案例的更改,該主題現在只有2個分割槽。我們現在正在改變我們的一個消費者的群組ID。
@KafkaListener(topics = <font>"advice-topic"</font><font>, clientIdPrefix = </font><font>"bytearray"</font><font>,
containerFactory = </font><font>"kafkaListenerByteArrayContainerFactory"</font><font>,
groupId = </font><font>"tpd-loggers-2"</font><font>)
<b>public</b> <b>void</b> listenAsByteArray(ConsumerRecord<String, byte[]> cr,
@Payload byte[] payload) {
logger.info(</font><font>"Logger 3 [ByteArray] received a payload with size {}"</font><font>, payload.length);
latch.countDown();
</font>
請注意,我們還更改了記錄的訊息。現在,這個消費者負責列印payload有效載荷的大小。此外,我們需要更改CountDownLatch 它,因此它需要兩倍的訊息數。
latch = new CountDownLatch(messagesPerRequest * 2);
為什麼?這一次,讓我們解釋在執行應用程式之前會發生什麼。正如我在本文開頭所描述的那樣,當消費者屬於同一個消費者群體時,他們(在概念上)正在處理同一個任務。我們正在實現一種負載均衡機制,其中併發工作程式從會不同分割槽獲取訊息,處理的訊息是彼此隔離的。
在這個例子中,我還改變了最後一個消費者的“任務”,以便更好地理解這一點:它列印的是不同的東西。由於我們更改了組ID,因此該消費者將獨立工作,Kafka將為其分配兩個分割槽。位元組陣列消費者將接收所有訊息,與其他兩個訊息分開工作。