論文筆記:目標檢測演算法(R-CNN,Fast R-CNN,Faster R-CNN,YOLOv1-v3)
摘要:
R-CNN(Region-based CNN)
motivation
:之前的視覺任務大多數考慮使用SIFT和HOG特徵,而近年來CNN和ImageNet的出現使得影象分類問題取得重大突破,那麼這方面的成功能否遷移到PASCAL VOC的目標檢測任務上呢?基於這個問...
R-CNN(Region-based CNN)
- motivation :之前的視覺任務大多數考慮使用SIFT和HOG特徵,而近年來CNN和ImageNet的出現使得影象分類問題取得重大突破,那麼這方面的成功能否遷移到PASCAL VOC的目標檢測任務上呢?基於這個問題,論文提出了R-CNN。
- 基本步驟 :如下圖 所示,第一步輸入影象。第二步使用生成region proposals的方法(有很多,論文使用的是seletivce search,ImageNet2013檢測任務的冠軍UVA也使用了該演算法)提取約2000個候選區域。由於CNN固定輸入大小所以第二步和第三步之間需要做一個warped region。第三步將2000個候選區域分別輸入到CNN(AlexNet)計算2000個特徵向量,第四步將各個特徵向量(4096維,相比於之前常用的方法UVA減小了2個量級,4k vs 360k)輸入到(類特定的)各個線性SVM中分類(比如VOC的20個類別就有20個SVM)。對於特定類的SVM,由於有2000個候選區域,所以有2000個結果,使用非極大值抑制來獲得得分較高的一些候選區。
- CNN的訓練 :使用的CNN在ImageNet2012分類資料集上做了預訓練。微調時把最後的1000類改為N+1類,對於VOC而言N為20,對於ImageNet2013檢測資料集而言N為200,以IOU大於等於0.5為正樣本,其它為負樣本,學習率0.001,每次SGD迭代(128的batch size)中用了32個正視窗(所以類上)和96個背景視窗。
- SVM的訓練 :以0.3作為IOU閾值來選取正負樣本。由於負樣本太多,採用hard negative mining的方法在負樣本中選取有代表性的負樣本。
- R-CNN BB :為了提高定位表現,額外使用了一個bounding box regression。用第五個池化層的特徵輸入到SVM獲取得分,然後(根據最大IOU)構建候選區域和真實區域的資料集,訓練一個迴歸器,可以對候選區域的位置修正。
- 結果比較之VOC :在VOC 2007上調參,在VOC 2010-12上進行預測。CNN在VOC 2012訓練集上做微調,SVM在VOC 2012的訓練驗證集上進行訓練。超越了其它演算法。
- 結果比較之ImageNet2013 :OverFeat是ImageNet2013定位任務的冠軍,對於檢測任務在賽後也獲得了第一的成績(24.3%的mAP),是ImageNet2013檢測資料集(200類)上表現最好的檢測演算法(當時),而R-CNN用在ImageNet2013的檢測資料集上獲得了31.4%的mAP。

Fast R-CNN
- R-CNN的三個缺點 :多階段(訓練CNN,訓練SVM,訓練bb迴歸器);訓練時空間和時間代價高(對於SVM和bb迴歸器需要把每張影象的每個候選區特徵通過CNN提取出來存到磁碟);預測階段很慢(因為要對每張影象的每個候選區域提取特徵)。
- SPPnet的改進 :R-CNN預測慢是因為對於每個候選區域要過一次CNN而不共享計算,而SPPnet則是使用共享計算來加速。如下第一個圖 所示,SPP輸入整張圖,計算一個feature map,在feature map上找到候選區對應的一個子圖,然後對子圖做一個金字塔池化得到一個固定長度的特徵向量(下圖中得到的是4x4+2x2+1個特徵)。 儘管如此,SPPnet仍然有多階段以及特徵寫入磁碟的缺點,而且因為SPPnet的特徵是從conv5的feature map上池化而來的,所以只fine-tuning金字塔池化層之後的層(這限制了深層網路的準確性)。
- motivation :Fast R-CNN修正了R-CNN和SPPnet(Spatial pyramid pooling)的缺點,提升了速度和準確率。它是一個單階段的演算法,使用了multi-task loss,可以對整個網路進行更新,而且不需要把特徵存到磁碟上。
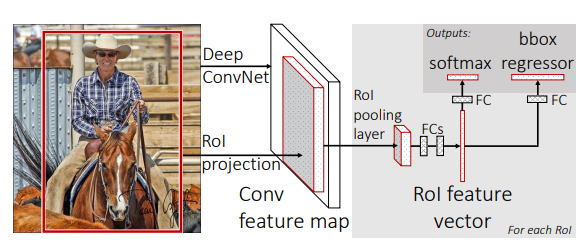
- 主要步驟 :如下第二個圖 所示,輸入為一整張圖以及一系列的(selective search生成的)候選區域(對映到conv5的feature map上得到ROI),ROI意為Region of Interest。像SPPnet一樣對ROI進行池化,只不過這裡是單水平的金字塔池化(如下第一個圖是三水平),比如分成7x7個子圖對每個子圖取最大得到長度為49個ROI特徵。池化後經過FC,然後分成兩個分支,一個分支用softmax做分類,一個分支用bb迴歸器做定位,使用multi-task loss進行訓練。
- mini-batch sampling :R-CNN和SPPnet在微調訓練時每個batch是從128張影象中分別取一個RoI。而Fast取N個影象,每個影象取R/N個ROI(論文中使用N=2,R=128),這樣來自同一個影象的ROI在前向和後向過程中就可以共享記憶體和計算,提高了效率。取樣時25%的ROI是從IOU為0.5以上的侯選框選的,剩餘的ROI是從IOU為[0.1, 0.5)中的侯選框選的。
- SGD超參 :softamx和bb迴歸器的全連線層使用0均值,0.01和0.001的標準差的高斯分佈進行初始化。bias為0。所有層的權重學習率為1倍的全域性學習率,偏置為2倍的全域性學習率,全域性學習率為0.001。對於VOC07或者、VOC12的訓練,30k次迭代,然後學習率減為0.0001然後訓練另外10k次迭代。momentum為0.9,weight decay為0.0005。
- 截斷的SVD :將龐大的全連線層壓縮為截斷的SVD可以提高檢測速度。
- 應該微調哪些層 :消融學習中,固定前面的卷積,只微調後面的全連線層(像SPPnet那樣)發現mAP下降,說明微調前面的卷積層是重要的。那麼是不是說所有的卷積層都應該被微調呢,不是, 通過實驗發現conv1對mAP影響不大,對於VGG16,發現只需要更新conv3_1以及以後的層。
- 其它實驗和討論 :通過實驗,發現單尺度可以獲得和多尺度差不多的結果,所以論文的實驗都是使用單尺度。通過實驗,發現更多訓練資料可以提高mAP。通過實驗,發現softmax比SVM好一點點,差距不大。通過實驗,發現隨著候選區數量的增加,mAP先增後降,說明不是越多越好。將Fast執行在COCO資料集上建立一個初步baseline。

Faster R-CNN
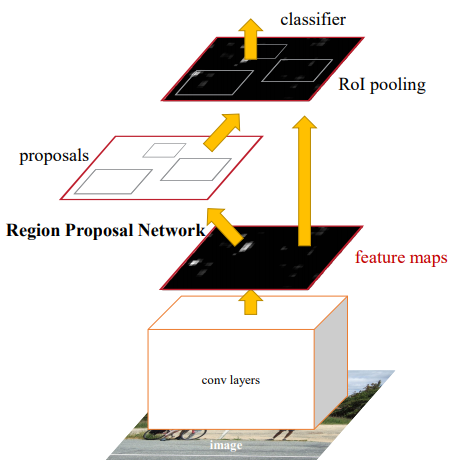
- motivation :Fast R-CNN的瓶頸在於生成候選區域(Selective Search的)的方法非常耗時,Faster提出把生成候選區域也放到卷積網路來做(網路稱為RPN,Region Proposal Networks),將RPN和檢測網路(Fast R-CNN)結合成一個網路進行統一的訓練和檢測,這樣可以共享卷積操作,減小計算時間。實驗也表明了Faster可以提高檢測表現。
- 主要步驟 :如下第一個圖 所示,在原來網路的最後一層卷積層加入一個RPN來生成ROI,然後根據feature map和ROI進行ROI池化,後面和Fast一樣再接全連線,softmax和迴歸器。
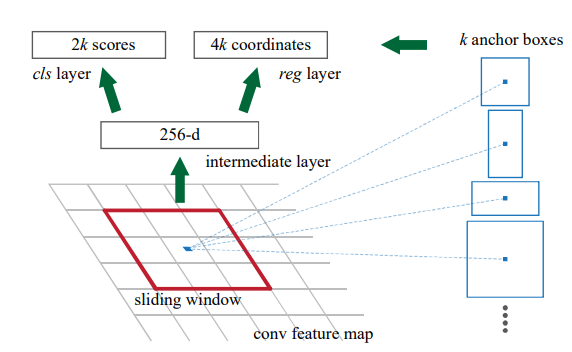
- RPN接面構 :設計如下第二個圖 ,RPN在最後一個卷積層上以nxn的視窗滑動進行卷積(論文中n為3,所對應的感受野是很大的),每個視窗(一小塊3x3的區域)被對映成低維特徵(ZFnet-256d,VGG-512d),然後分為兩路接兩個1x1卷積得到分類層和迴歸層。其中k表示事先設計的k個anchor(論文中k為9,3種scale和3種寬高比組合),分類層的2k個單元中的2表示是或不是,迴歸層的4k個單元中的4表示目標對應的座標位置。最後會根據這兩個層計算一個損失進行訓練。
- 訓練RPN :訓練時,和某個grouth truth的IoU值最高的anchor視為正樣本,和任意ground truth的IoU超過0.7的anchor也視為正樣本。和所有ground truth的IoU低於0.3的視為負樣本,其它的忽略,超出原圖邊界的anchor也忽略(如果測試階段得到這種anchor,則clip到邊界)。一個mini-batch(256)為一張影象的多個anchor,正負比例為1比1。共享卷積層遵循R-CNN的實踐進行ImageNet分類的預訓練來對引數初始化,對ZFnet調整整個網路,對VGG微調conv3_1以上的層。其它新增層(RPN)用(0,0.01)的高斯分佈初始化引數。前60k次mini-batch使用0.001的學習率,後20k次mini-batch使用0.0001的學習率,在VOC資料集上。momentum為0.9,weight decay為0.0005。
- RPN和檢測網路(Fast R-CNN)的訓練 :論文采用的是交替訓練的方式,第一步按上述步驟訓練RPN。第二步用RPN產生的候選區域訓練檢測網路,檢測網路也進行了預訓練,到這一步,二者不共享前面的公共卷積層。第三步用檢測網路的引數初始化RPN前面的公共卷積層,微調RPN,此時RPN和檢測網路共享前面的卷積層。第四步,微調檢測網路的後半部分(固定公共卷積層)。另外,RPN產生的區域可能高度重疊,根據RPN的分類分數,使用非極大值抑制(0.7的IOU閾值)來減小候選區域數量。
Yolo(You Only Look Once)v1
- motivation :與R-CNN系列演算法(產生候選區域,分類,迴歸修正)不同,yolo直接用一個單獨的卷積網路輸入影象,輸出bb(bounding box)和分類概率。
- 優點 :第一是更快(不需要像R-CNN系列那樣複雜的步驟)。第二是站在全域性的角度(可以看到整張影象)去預測,可以產生更小的背景誤差。第三是能學到泛化能力強的特徵(實驗表明)。
- 缺點 :第一是施加了很強的空間限制,導致系統能預測的目標數量有限,而且對靠的很近的物體和很小的物體的檢測效果不好。第二是難以泛化到新的不常見的長寬比物體。第三是損失函式對小bb和大bb的誤差同等對待,小誤差對大bb來說沒什麼,但是對小bb來說影響很大,yolo的主要錯誤就是來源於定位錯誤。還有一點是準確率無法達到state-of-art的水平。
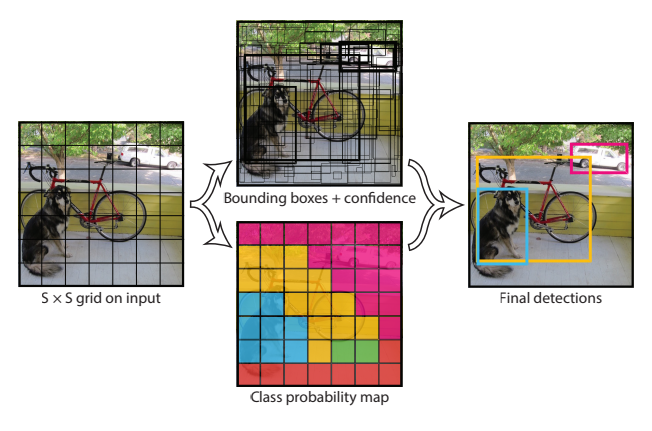
- 主要思想 :如下圖 所示,將輸入影象劃分為SxS的格子,目標(物體)的中心落在哪個格子內,就由哪個格子負責。每個格子檢測B個bb和C個類別的條件概率。每個bb包含5個值(x, y, w, h, 置信度),其中x和y相對於格子歸一化到0到1,w和h相對於整張影象歸一化為0到1,置信度定義為\(Pr(Object)*IOU_{pred}^{truth}\) ,我們希望“如果沒有物體則置信度為0,如果有物體,Pr為1,置信度表示為IOU"。C個類別的條件概率為\(Pr(Class_i | Object)\) 。測試階段用條件概率乘上置信度,得到一個類相關的置信度。所以最後輸出層的單元數字應該為SxSx(Bx5+C),論文中S為7,B為2,C為20類(VOC資料集),所以輸出是一個7x7x30的tensor。另外,對於一個大物體,可能出現多個格子對它負責預測,這個時候使用非極大值抑制處理。
- 訓練 :網路結構參考GoogleNet做了修改。在ImageNet上做了1000類分類的預訓練,然後增加捲積層和全連線層,把224的輸入改成448(檢測需要更細粒度的視覺資訊)。輸出層使用線性啟用,其它層使用leaky relu。在VOC07和12的訓練集和驗證集上訓練了135個epochs,在VOC12測試時也使用(加入)了VOC07的測試集進行訓練。batch size 為64,momentum為0.9,weight decay為0.0005。學習率在第一個epoch從0.001緩慢升到0.01,如果一開始使用高學習率會由於不穩定的梯度導致模型不收斂。然後0.01訓練75個epochs,0.001訓練30個epochs,0.0001訓練最後30個epochs。為了防止過擬合使用了dropout(第一個連線層之後,0.5)和資料增強。
- 損失函式 :如下(論文中給出的)式子所示。損失函式把定位誤差和分類誤差平等對待可能不太好,而且一張影象可能很多格子是沒有物體的,使得置信度幾乎為0,這壓制了確實有物體的格子的梯度,使得模型不穩定。所以需要減小不含物體的bb的置信度帶來的損失(給予一個0.5的權重\(\lambda_{noobj}\) ),增加bb座標帶來的損失(給予一個5的權重\(\lambda_{coord}\) )。損失函式把大bb和小bb平等對待也不太好,為了一定程度上彌補這個問題,對於寬度和高度,使用它們的平方根來代替它們本身。
-
其它
:關於yolo之前在ng深度學習課程中有所瞭解,具體筆記見:ofollow,noindex" target="_blank">ng-深度學習-課程筆記-目標檢測
。
\[\lambda_{coord}\sum_{i=0}^{S^2}\sum_{j=0}^{B}\mathbb{1}_{ij}^{obj}[(x_i-\hat{x}_i)^2+(y_i-\hat{y}_i)^2] + \\ \lambda_{coord}\sum_{i=0}^{S^2}\sum_{j=0}^{B}\mathbb{1}_{ij}^{obj}[(\sqrt{w_i}-\sqrt{\hat{w}_i})^2+(\sqrt{h_i}-\sqrt{\hat{h}_i})^2] + \\ \sum_{i=0}^{S^2}\sum_{j=0}^{B}\mathbb{1}_{ij}^{obj}(C_i - \hat{C}_i)^2+ \lambda_{noobj}\sum_{i=0}^{S^2}\sum_{j=0}^{B}\mathbb{1}_{ij}^{noobj}(C_i - \hat{C}_i)^2 + \\ \sum_{i=0}^{S^2}\mathbb{1}_{i}^{obj}\sum_{c \in classes}(p_i(c)-\hat{p}_i(c))^2\]
Yolov2
- yolov2 :從yolov1到yolov2增加了一系列設定來改善yolo,如下第一個圖 所示。
- hi-res classifier :表示在正式訓練檢測網路(448x448)之前先使用448x448輸入影象的分類網路進行預訓練(在這之前已經在ImageNet上進行224輸入影象的預訓練)。
- convolutional和anchor boxes :表示借鑑Faster的做法,去掉迴歸層之前的全連線和池化,在最後一層卷積層上進行anchor box的預測,此舉雖然降低了mAP,但是提高了recall(81到88)。在v1中類別是分配到格子的,所以是最後tensor大小是SxSx(Bx5+C),C是類別。而v2中每個格子設計多個anchor box(表示每個格子分配多少個bb),類別分配到了格子的bb中,所以最後tensor大小是SxSxBx(5+C)。
- new network :表示使用新的網路結構作為檢測的基礎網路,借鑑了VGG和NIN,提出了Darknet-19。
- dimension prior :表示使用k-means聚類來設計anchor的形狀。
- location prediction :表示不預測offset(Faster中anchor的預測方式),而是沿用yolov1直接預測相對格子的歸一化座標。
- passthrough :表示將最後一層feature map(13x13)和上一層(26x26)調整後的feature map進行concat,因為對於小目標通過層層卷積後可能就不見了,所以連線一下上一層的特徵圖。
- multi-scale :表示的是多尺度訓練。
- hi-res detector :表示使用更高解析度的輸入影象。
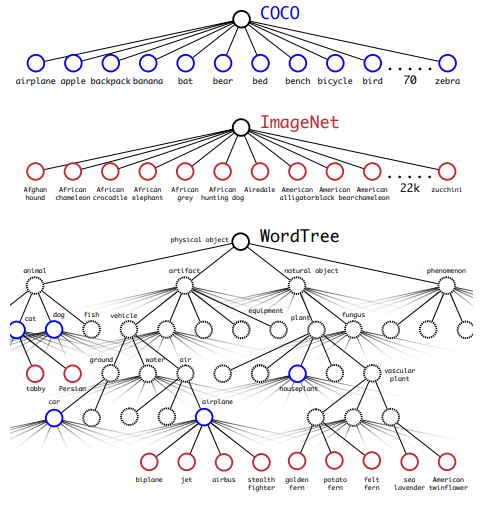
- yolo9000 :yolo9000以yolov2為主網路,通過聯合優化分類和檢測的方法,同時訓練兩個資料集(WordTree結合了ImageNet和COCO的資料集),使得系統能夠檢測超過9000類的物體,其中WordTree如下第二個圖所示。

Yolov3
- bb預測 :對於每個bb的objectness score使用邏輯迴歸。當bb是某個ground truth的最大IOU時則應該預測為1。假如bb並不是最高的,只是(跟ground truth的)IOU大於某個閾值,則忽略預測,跟Faster一樣。和Faster不一樣的是,對於ground truth只分配一個bb。如果一個bb沒有被分配到ground truth就沒有座標損失和分類損失,只有objectness損失。
- 類預測 :每個bb的分類預測使用獨立邏輯迴歸以及binary cross-entropy而不使用softmax。這樣有助於遷移到更復雜的領域(比如Open Image Dataset中存在重疊標籤,比如女人和人),而softmax假定了一個box只屬於某一個類。
- 跨尺度預測 :借鑑FPN(feature pyramid network)的做法,從三個不同尺度上提取特徵,主要就是把前層的feature map拉過來做上取樣然後concat。COCO的實驗中,每個尺度預測3個boxes所以tensor為NxNx[3x(5+80)],80表示類別。
- 特徵提取 :在Darknet-19基礎上加入了殘差結構,提出了Darknet-53。
參考文獻
- R-CNN(2014 CVPR):Rich feature hierarchies for accurate object detection and semantic segmentation (模型原始碼-caffe(matlab)實現 )
- Fast R-CNN(2015 ICCV):Fast R-CNN (模型原始碼-caffe實現 )
- Faster R-CNN(2015 NIPS):Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks (模型原始碼-caffe實現 )
- Yolov1(2016 CVPR):You Only Look Once: Unified, Real-Time Object Detection (模型原始碼-darknet(C和cuda) )
- Yolov2(2017 CVPR):YOLO9000: Better, Faster, Stronger (模型原始碼-darknet(C和cuda) )
- Yolov3:YOLOv3: An Incremental Improvement (模型原始碼-darknet(C和cuda)實現 )