視語科技王金橋團隊榮獲2018全球AI挑戰賽冠軍,演繹演算法與工程的完美結

2018年12月20日,“AIChallenger2018全球AI挑戰賽”年度總決賽圓滿落幕,視語科技創始人兼董事長、中科院自動化所研究員王金橋帶領團隊獲得“無人駕駛視覺感知”賽道冠軍!以高於第二名四倍的成績遙遙領先,並得到“達到世界級領先水平”的極高評價。美團點評無人配送視覺感知技術負責人陳華清讚歎道,“太強了,這樣的成績讓人驚喜”。
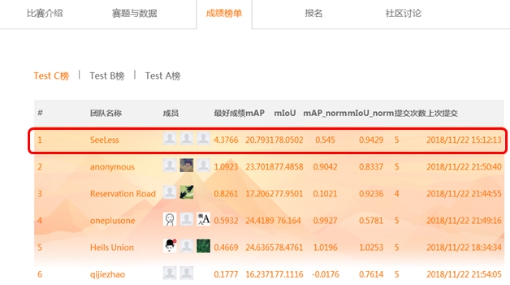
“AI Challenger全球AI挑戰賽”是國內規模最大的、最關注前沿科研與產業實踐相結合的非商業化資料集和競賽平臺。本次大賽於2018年8月29日正式啟動,吸引了來自81個國家的1100所高校和990家公司的上萬支團隊參賽,而王金橋團隊就是這萬里挑一的佼佼者,展示了在視覺識別領域的領先水平。
2018年是人工智慧落地的元年,人工智慧實際上是一個將數學、演算法理論和工程實踐緊密結合的領域。演算法只有深度與場景融合,實現產學研一體化,解決行業痛點才能真正實現人工智慧的價值。視語團隊從演算法設計、資料處理、工程優化等幾個方面介紹如何將視覺識別演算法與應用場景進行深度融合,打造有溫度、有價值的AI技術。
1.演算法是核心
科研中演算法的比拼相當於華山論劍,講究的是科學性、原創性和實驗效果。而在工程落地中,更注重演算法與場景適配性、穩定性、精度和速度。經常需要針對特定場景下的特定任務,定製整體演算法框架,對每一個演算法細節進行精細打磨,併合理利用演算法和場景結合的邊界,從而提出一些創新型的思路。
以無人駕駛視覺感知為例,需要同時解決“目標檢測”和“可行駛區域分割”兩個子問題。而由於計算資源有限,為了追求精度和速度的平衡,演算法設計需要考慮多工學習框架。


接下來,需要深入剖析子問題的難點,對演算法各個模組進行定製化設計。比如對於目標檢測來說,該應用場景需要儘量提高各類目標的檢出率,所以小目標檢測就成為難點,這裡的小目標包括交通標誌、交通燈、遠處的行人和車輛等。對於可行駛區域分割來說,主要難點在於類間定義模糊,即可直接行駛區域和可間接行駛區域之間有時候界限並不是很清晰。本質上可行駛區域就是道路,但是對於雙車道來說另一側車道就是背景了,所以對於可行駛區域分割來說需要演算法具有較強的上下文語義感知能力。
基於上述分析,視語團隊提出了一種多工耦合神經網路的解決方案。具體來說,針對速度方面的要求,從三方面進行優化:第一是多工學習,一個網路同時處理檢測和分割兩個任務,使它們儘可能多地共享耦合特徵計算;第二是設計輕量級的多尺度耦合網路,降低網路本身的計算量,並進一步裁剪預測頭;第三是程式碼優化,包括batch輸入、GPU解碼、CPU解碼+流水處理等。考慮到解碼部分耗時較高,團隊將圖片解碼放到GPU上進行實現,以充分利用GPU的併發性來加速解碼;同時形成前處理(CPU)、網路前向(GPU)以及後處理(CPU)的流水式操作,用網路前向的時間掩蓋CPU讀圖和寫圖的時間。
為了有效提升模型的精度,團隊採用了三種有效的策略。第一是使用特徵金字塔,主要是改善小目標檢測精度;第二是使用空間金字塔池化ASPP模組,主要是增強網路的上下文語義感知能力;第三是引入資料蒸餾,進一步優化輕量級網路的效能。基於上述策略,團隊提出了一個面向多工的耦合神經網路(MCoupleNet),能夠同時處理目標檢測和可行駛區域分割兩個任務。整個網路包含了5個模組:基礎網路、ASPP、特徵金字塔、檢測分支以及分割分支。基礎網路部分是團隊自主設計的輕量級網路Inception-56,基礎網路和特徵金字塔之間通過ASPP模組連線在一起,ASPP模組由一系列採用不同膨脹係數的卷積層組合,可以同時捕捉多種上下文資訊,並加入深層監督來引導整個學習過程。

特徵金字塔的設計可以參考團隊在ACCV16發表的工作以及Facebook發表於CVPR17的論文。ACCV16的論文主要用來處理監控場景下不同尺度的行人,通過自適應的上取樣模組在不同解析度的特徵圖上處理不同尺度的行人目標,Facebook CVPR17的論文進一步引入lateral connections並且推廣到通用目標檢測上,是目前比較成熟的解決目標多尺度的演算法。團隊在此基礎上加入基本的檢測分支和分割分支,從而組成一個多工的學習框架。
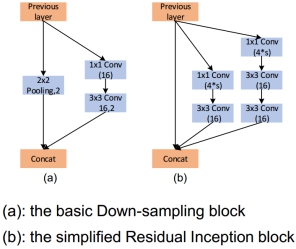
輕量級耦合網路主要包含兩個模組:基本的下采樣模組和簡化版的殘差Inception模組。基本的下采樣模組主要應用在網路的早期,用來快速下采樣從而減少計算量,同時改善特徵表達能力。簡化版的殘差Inception模組使用了更少的通道數,在每次下采樣的時候通過兩個1x1的維度擴充卷積、動態的增加一倍的通道數,用來補償空間解析度損失。不同於MobileNet和ShuffleNet,該輕量級網路中所有的卷積都是常規卷積,沒有group卷積和depthwise卷積,因此能夠適用於所有的平臺,並且有助於減少MAC(memoryaccess cost),同時所有的卷積後邊緊跟著BN和ReLu,最終網路的計算量只有143M。
除了基礎網路之外,對新加入的特徵金字塔也需要進一步的調整。尤其是高解析度輸入下,演算法的各個部分都有可能成為計算瓶頸。以720P輸入為例,特徵金字塔部分的通道數預設為256,網路上取樣的倍率為4,對於特徵金字塔中的一個3x3的卷積層,其計算量#FLOPS=3*3*256*256*184*320=34.7G,非常大!所以特徵金字塔部分也需要進行裁剪,並且對輸入解析度和上取樣倍率之間也需要進行權衡。
最終,團隊憑藉上述原創的演算法設計方案,在2018全球AI挑戰賽無人駕駛視覺感知賽道中取得了效能的遙遙領先。
2.資料是血液
眾所周知,沒有人工就沒有智慧,當今深度學習演算法的成功依賴於大規模精確標註的訓練資料。因此,資料的採集和標註也是演算法落地的關鍵環節。為了提高演算法開發的效率,大多數公司都會為演算法團隊配備一個數據團隊或者通過外包公司,專職負責資料的採集、篩選、標註工具或者平臺的開發、標註、資料統計與管理等工作。
不同於學術研究中直接使用公開資料集的方式,實際應用中,經常需要針對特定任務特定場景進行大量資料採集。然後在資料標籤類別大於1萬的時候,資料標註的成本成級數級增長,而且對於某些稀缺資料,難以收集樣本。因此基於小樣本的模型訓練或者採用弱監督來利用大量未標註的樣本成為未來發展的主流,還可以藉助3D虛擬合成和GAN生成的方式來生成訓練資料。此外,為了充分高效地利用資料,跨任務的資料複用和基於演算法的資料清洗也是提升演算法開發效率的有效策略。最後,演算法在上線使用過程中,源源不斷產生的資料也可以反過來進一步推動演算法效能的提升。
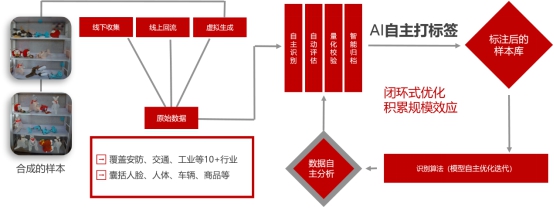
視語團隊針對檢測、分割、分類等不同計算機視覺任務,利用多年來在安防、交通、零售、工業檢測等10多個行業的人臉、人體、車輛、商品、布匹等多型別海量資料積累,推出了國內第一個基於主動學習的半自動化標註平臺。以海量資料學習為基礎,集主動識別、自動評估、量化校驗、智慧歸檔為一體,形成樣本自主標註、模型自主更新、資料自主分析的閉環系統。其中的虛擬生成環節,可以實現資料樣本自動旋轉、自動形變、自動渲染,目標前景背景自動分割、自動標籤對映。最終實現100%的標註準確率,有效替代95%的人力標註成本,形成資料採集+演算法研發的深度結合,打造閉環系統開發流程。
3.工程是關鍵
產品和系統的最終部署上線,離不開精心的工程優化。工程化能夠在優秀的演算法與成熟的應用之間架起一座橋樑,使得演算法能夠充分發揮其效能優勢,使得應用能夠達到最優效果。典型的工程優化流程包含硬體的選擇、面向特定硬體平臺的網路設計、演算法底層優化、系統資源合理排程等內容,是需要在演算法方案設計之初就綜合軟硬體特性、應用場景特點綜合考慮的問題。
演算法的部署首先需要依託特定的硬體載體,其中不同的硬體平臺有著截然不同的特性,如何根據應用場景的特點、硬體平臺的特性、以及對應的成本/功耗等問題選擇合理的硬體平臺是演算法是否能夠成功應用的基礎條件。例如Nvidia的大型GPU(如1080Ti、Titan V100等)具有大視訊記憶體、高計算力等優勢的同時也會伴隨著高功耗、大空間、高成本等劣勢,其通常部署在雲端,以雲服務的形式提供線上服務支撐,在滿足我們日常的網路模型訓練任務的同時,可以在後臺承擔高併發、高複雜度等對算力要求較高的任務,如面向監控市場的視訊結構化任務,通常需要併發處理幾十路甚至上百路的實時視訊流,或者需要20倍速以上處理本地視訊檔案,這就需要GPU強大算力的支撐。而對於面向移動端(手機、智慧前端分析裝置、智慧攝像頭)的應用,則需要更多的考慮受限的算力以及對功耗的控制,因此更傾向於選擇低功耗的諸如Arm、FPGA、DSP或者面向神經網路加速的ASIC晶片進行對於場景的適配,如海思的Hi3559A晶片,在集成了神經網路加速引擎NNIE的同時,還具備豐富的外圍介面支援(視訊編解碼、ISP等),是作為智慧前端裝置主晶片良好選擇。而諸如MediaTek3288/3399等Arm晶片雖然算力一般,但卻具有低功耗、低成本的優勢,在諸如人臉抓拍等特定領域也有著不小的優勢。因此,擁有明確、清晰的應用場景定位和需求分析,選擇合理的硬體平臺,是演算法產品化、實用化的首要條件。
在確定的硬體平臺上,如何充分發揮受限的計算資源又會反推演算法設計時進行相應的考慮和適配。如面向CPU(x86、ARM)平臺時,通常需要更多的採用Depthwise,或者Shuffle Layer等對CPU運算友好的結構進行網路結構設計,而面向FPGA平臺時,需要考慮網路結構的可稀疏化、同時網路設計的同時應當考慮低bit量化後的精度保持問題,同時在網路結構的設計中更多的考慮採用可以進行特定數學方法優化實現的(winograd)特殊卷積層,如大小為3*3的卷積核等。而面向特定的硬體計算平臺(如Hi3559A)時,模型對量化、常見層的選擇則會有更加差異化的要求。
在網路結構確定、演算法框架確定的基礎上,還需要在演算法實現上充分考慮不同硬體平臺特性進行特定優化。如Nvidia GPU平臺下可以優先考慮TensorRT推理引擎,另外應當儘量選擇CUDA程式設計對演算法進行實現,減少CPU-GPU資料互動以提高GPU利用率,調整合適的batch size大小以充分呼叫GPU計算資源等。而面向CPU平臺下的實現通常應當更多的考慮SIMD指令集的優勢,如在Intel x86架構下應當充分利用SSE、AVX指令集對演算法進行深度優化,或者考慮採用OpenVino計算庫對演算法進行移植,而面向ARM架構,NEON指令集加速、執行緒池、記憶體池技術的應用通常有著巨大的收益。
除此之外,演算法的外圍開發工作也應當以“演算法算力資源優先”的原則進行設計,如在GPU平臺下,可以充分利用CPU的閒置資源進行視訊編解碼操作、設計多級流水結構以降低系統整體耗時等操作也有著很好的實踐效果。而針對ARM平臺下常見的大小核架構,如何充分排程多核協同工作,設計大核卷積、小核管理等策略也同樣十分重要。
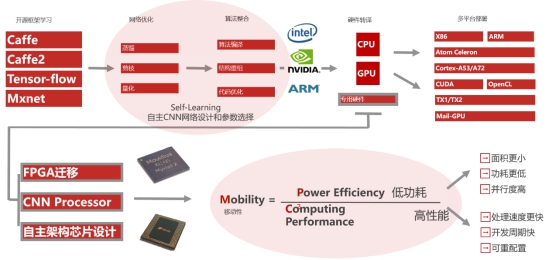
無人駕駛視覺感知賽題追求模型的輕量與快速。視語團隊在比賽過程中,針對GPU平臺在設計了輕量級的神經耦合網路結構、提出了端對端多工學習框架的同時,就採用了包括運算元GPU移植、多作業模組流水化處理、CPU-GPU併發處理等大量的工程優化策略來對演算法的實現過程進行改進,使得演算法最終在原始演算法版本上有超過200%的效率提升,演算法在GPU上的部署,正是通過視語團隊經過多年積累,所打造的跨平臺神經網路高效能推理引擎MNIE進行的。
該平臺緊跟邊緣計算的發展趨勢,在網路設計、模型部署時能夠自適應的適配不同硬體平臺,追求計算的高效能和低功耗之間的動態平衡。目前MNIE推理引擎支援神經網路模型在GPU、Arm、x86-CPU、FPGA、ASIC專用晶片上的優化部署,以充分發揮對應平臺的特性,同時能夠很方便的接入一些具有神經網路加速功能的特定裝置,如Hi3559a、movidus等。同時該推理引擎在外圍提供一套完整的工程化演算法部署策略,在諸如視訊編解碼、片上晶片資源排程方面具有良好的優化。採用該引擎部署的人臉檢測演算法,能夠在諸如樹莓派等低端ARM裝置上實現720P的實時人臉檢測。